Vera Rubin Decoded Pt. 6 | Supply Chain - Master Reference

⚠️ Educated guess, not a definitive supplier list. This part is an educated guess assembled by aggregating publicly-available research and institutional-source data — sell-side analyst notes, supplier earnings transcripts, OCP / GTC disclosures, Korean and Taiwanese industry reporting, and primary corporate filings. Vendor relationships, share splits, and revenue allocations across the Vera Rubin platform are largely under NDA. Treat everything below as a directional reference, not authoritative — figures and supplier assignments may be incomplete, misattributed, or wrong, and the picture is moving quickly.
📝 Scope — component manufacturers only. This note covers suppliers involved in manufacturing the components that go inside the Vera Rubin platform — silicon foundry, memory, PCB / CCL, copper foil, liquid cooling, power delivery, NVLink optics, scale-out networking, system assembly partners. Server-market OEMs / ODMs that assemble finished systems for resale — Dell, HPE, Lenovo, Supermicro and similar — are out of scope and not covered here.
Cross-cutting view of suppliers by subsystem. For engineering context, see Vera Rubin Decoded — Part 2 / Vera Rubin Decoded — Part 3 (chips) and Vera Rubin Decoded — Part 4 / Vera Rubin Decoded — Part 5 (tray-to-rack assembly + power + networking fabric).
Where to Read What — Series Map
| Part | Title | Scope |
|---|---|---|
| 1 | Platform Framing & Architecture Map | Blackwell → Rubin platform thesis, headline specs |
| 2 | Rubin GPU — Engineering Deep Dive | Process node, SMs, HBM4, NVLink-C2C, package, CPX + Groq 3 LPX |
| 3 | Vera CPU & the Networking Silicon Family | Vera CPU, NVLink 6 Switch, ConnectX-9, BlueField-4, Spectrum-6 |
| 4 | Rack Assembly — Trays, PCB, and Cooling | HGX vs NVL72, compute tray modules, cableless midplane, PCB upgrade, liquid cooling |
| 5 | Rack Power and the Networking Fabric | Power delivery, HVDC, tray↔rack wiring, scale-up NVLink 6, scale-out InfiniBand + Ethernet |
| 6 | Supply Chain — Master Reference (this part) | Suppliers by subsystem across the entire stack |
Subsystem Index
- Silicon — Logic & Memory
- Substrate, PCB & CCL
- Liquid Cooling
- Rack-Level Power Delivery
- NVLink 6 — Scale-Up Interconnect
- PCIe 6.0 / Internal Interconnect
- Quantum-X800 — InfiniBand Scale-Out
- Spectrum-X — Ethernet Scale-Out
- System Integration & Assembly
- Cross-Subsystem Heatmaps
1. Silicon — Logic & Memory
Context:
- Vera Rubin ships with seven distinct silicon products — the original six Nvidia-designed chips (Rubin GPU, Vera CPU, NVLink 6 Switch, ConnectX-9, BlueField-4, Spectrum-6) plus the newly-licensed Groq 3 LPU.
- Groq 3 LPU (codename LP30) deployed inside the Groq 3 LPX rack — March 2026, ~USD 20B.
- All chips manufactured by external foundries.
- Memory comes from a separate DRAM ecosystem — HBM4 for GPU, LPDDR5X for CPU, DDR5 for switch hosts, on-chip SRAM for Groq.
Naming convention: LPU is the individual Groq chip (Groq 3 LPU = LP30); LPX is the unified rack system that houses 256 LPUs across 32 trays. The two are not interchangeable throughout this part.
Chip Architecture & ISA Lineage
The platform packs three different ISA families into a single rack — Nvidia GPU, ARM (two flavors), and x86 — plus Groq's TSP and the standard ARM BMC.
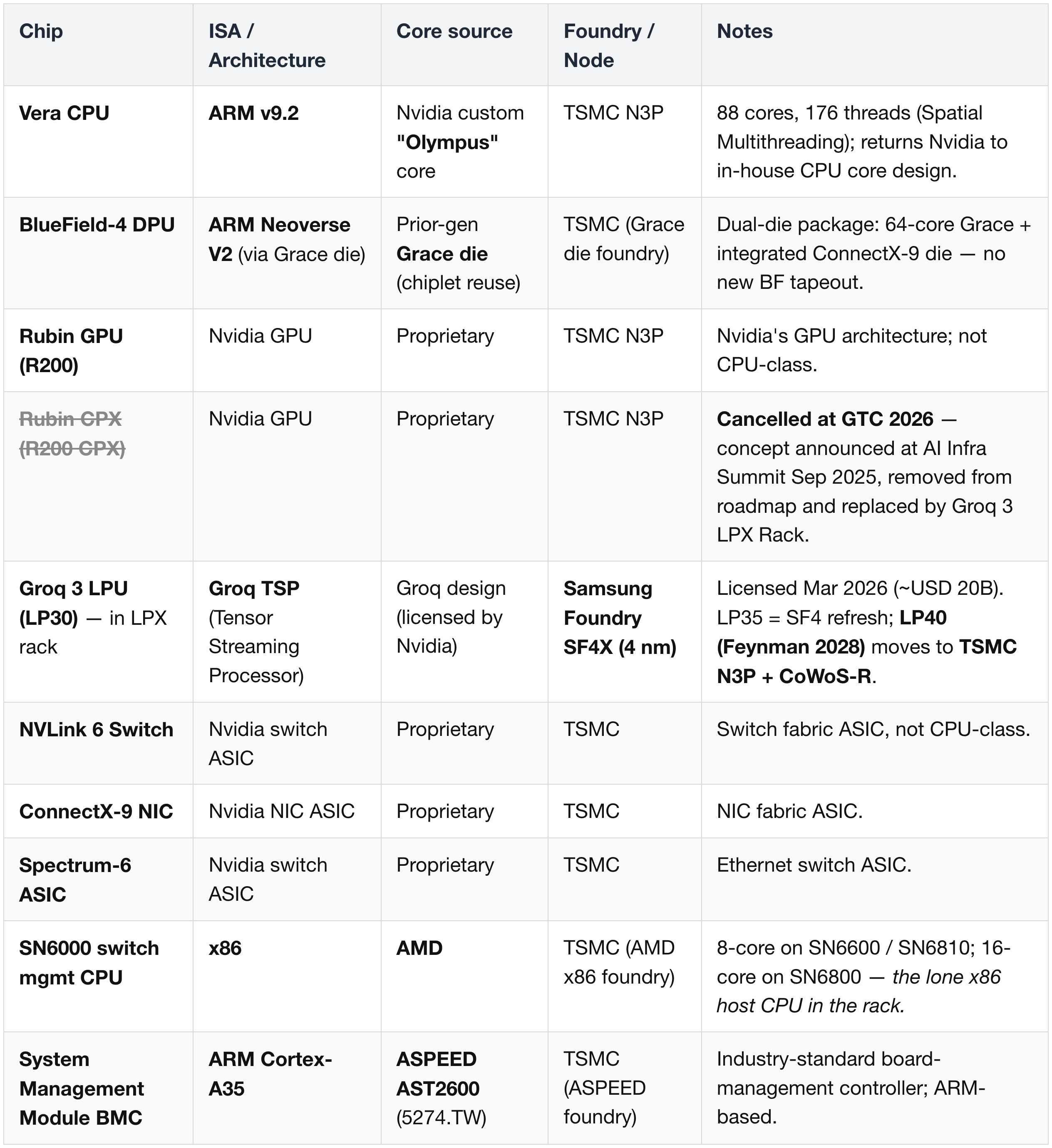
Reading the table:
- Two Nvidia ARM CPUs in the rack — Vera (new Olympus core, TSMC N3P) and BlueField-4 (reused Grace die).
- One AMD x86 CPU — the Spectrum-X switch host; an industry-default choice for switch management.
- One Groq TSP, manufactured by Samsung — the platform's only non-TSMC silicon today (LP30 / LP35 on SF4X), moving to TSMC N3P for the next-gen LP40 with the Feynman generation.
- Rubin CPX has been removed from the roadmap (GTC 2026); its prefill / decode workload bucket is now served by Groq 3 LPX Rack.
- AST2600 (ARM Cortex-A35) — the BMC on every reference SMM; standard across the industry.
Memory by Chip
Per-chip memory mapping — what kind, how many, who supplies it.
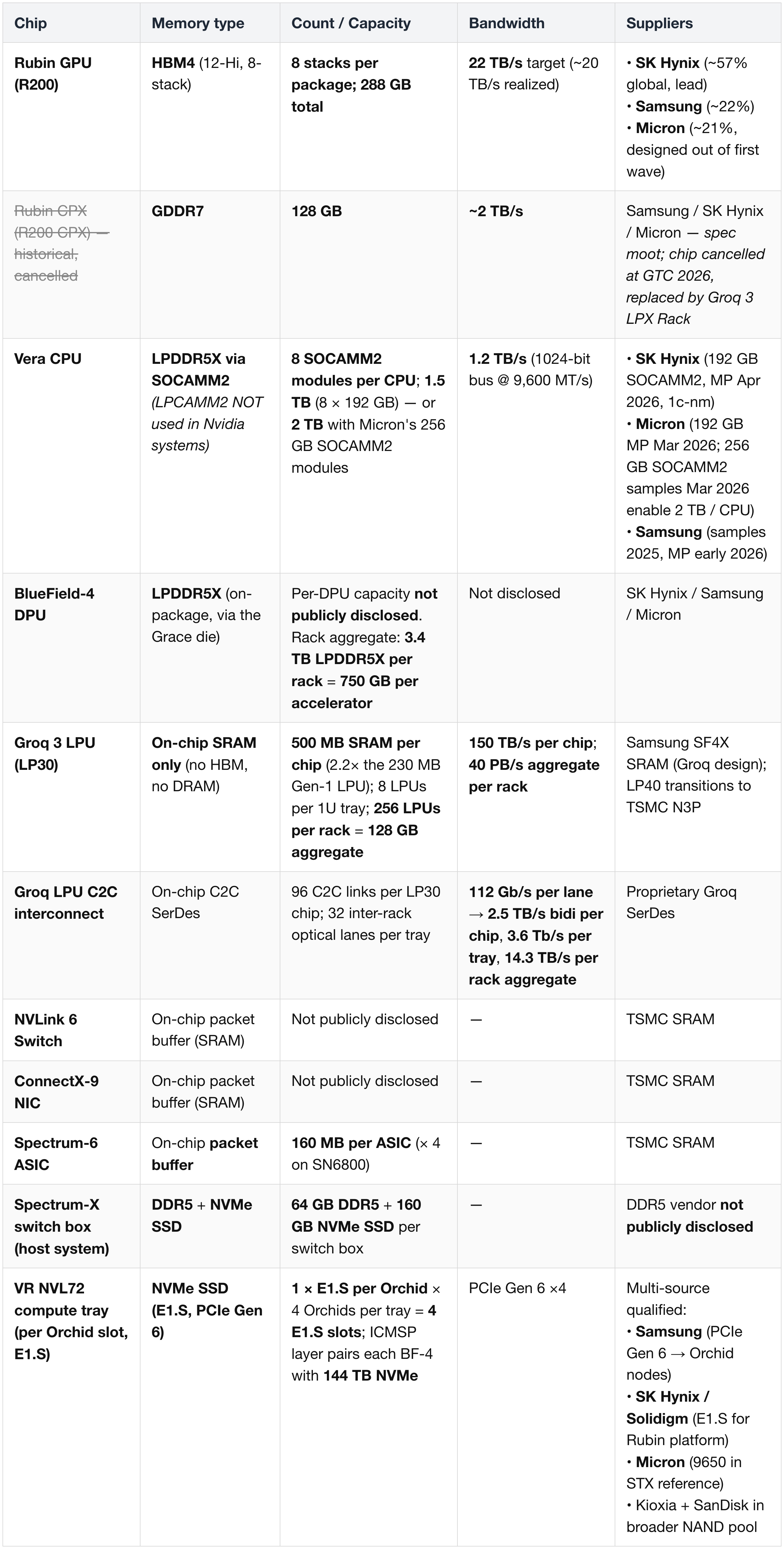
Reading the table:
- HBM4 is the highest-value memory bucket for the platform — 288 GB × 72 GPUs × 18 trays = ~20.7 TB of HBM4 per VR NVL72 rack.
- LPDDR5X is the highest-volume bucket — at the rack level, 3.4 TB LPDDR5X when counted across both Vera CPUs and BlueField-4 DPUs. Rubin will consume >6 B GB of LPDDR in 2027 (exceeds combined Apple iPhone + Samsung smartphones).
- Groq's SRAM-only design is the platform's biggest memory-economics divergence — replaces HBM bandwidth with on-die SRAM (40 PB/s aggregate per rack), no external DRAM at all. Targets the decode phase that Rubin CPX was originally meant to handle.
- SOCAMM2 vs LPCAMM2 — SOCAMM2 is Nvidia's proprietary server-optimized spec; LPCAMM2 is JEDEC client/laptop. Vera CPU uses SOCAMM2 exclusively, even for Micron's 256 GB "2 TB per CPU" path. All three vendors (Hynix / Micron / Samsung) supply SOCAMM2 for Vera Rubin.
Logic Foundry

- Capacity reality. Binding bottleneck is CoWoS-L advanced packaging, not logic-process wafers.
- Quoting Jensen Huang: Nvidia will be "supply constrained throughout the entire life of Vera Rubin".
Node Roadmap
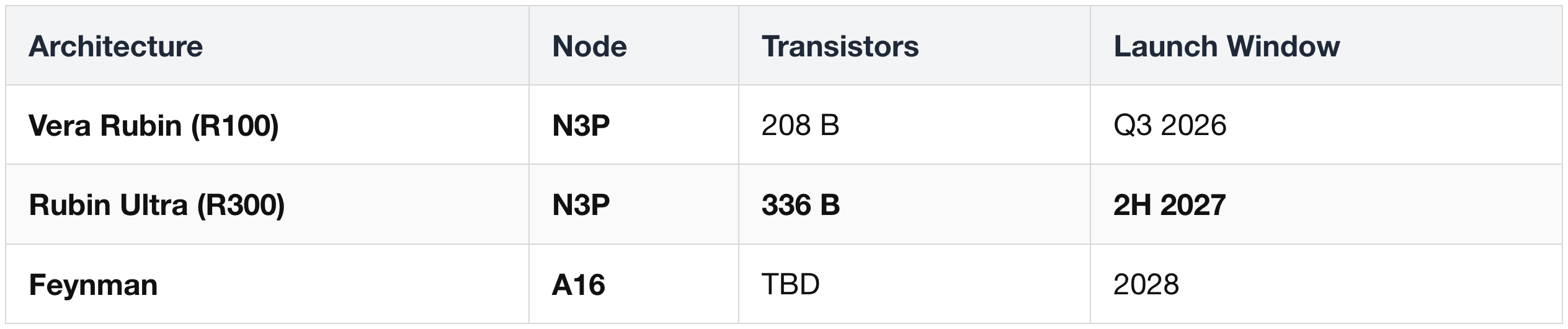
- Nvidia skipped N2 to align Feynman with A16 (backside power, 2027 volume).
- Apple (AAPL) holds >50% of TSMC's 2026 N2 capacity for A20 / M5.
HBM4 Memory (for Rubin GPU)
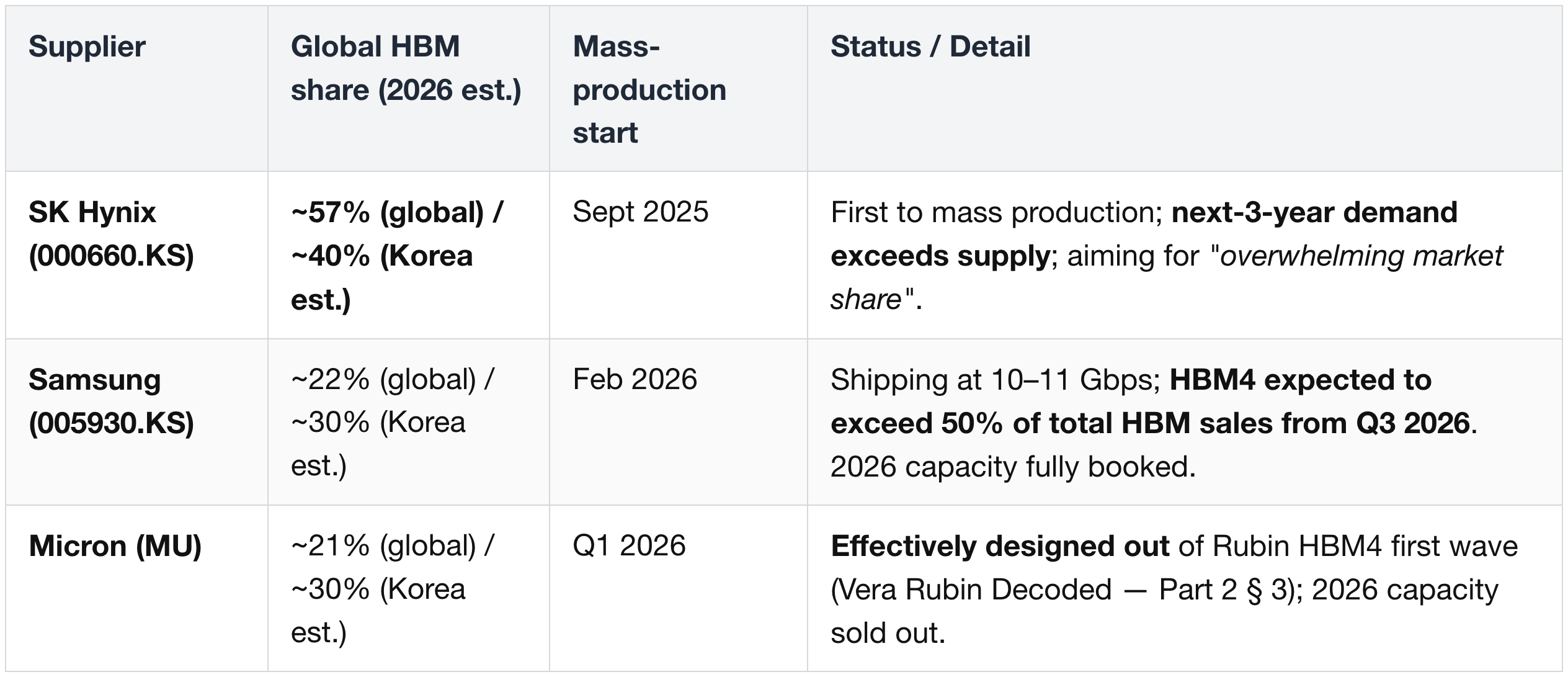
Reality at production: initial Rubin shipments are expected to land at ~20 TB/s (not the 22 TB/s headline target). All three vendors' 2026 HBM capacity is fully contracted under multi-year Strategic Customer Agreements with hyperscalers and Nvidia; pricing for large portions of 2026 was set in late 2025.
LPDDR5X (for Vera CPU — SOCAMM modules)
Micron is allocated ~30% of Vera's LPDDR5X, with Samsung and SK Hynix splitting the remainder. Notably, Micron gains meaningful share here even though it was largely designed out of HBM4 — LPDDR is a separate commercial allocation.

Demand-side scale: Rubin projected to consume >6B GB of LPDDR memory in 2027 — exceeding combined Apple (AAPL) iPhone + Samsung (005930.KS) smartphone LPDDR consumption.
SOCAMM2 socket supplier — Lotes (3533.TW)
- Confirmed SOCAMM2 socket supplier for Vera Rubin.
- Per-tray content: 8 SOCAMM2 modules per Vera CPU × 16 Vera CPUs = 128 SOCAMM2 modules per NVL72 compute tray.
- Platform total SOCAMM2 socket demand estimated at 8.7 M units.
- Lotes projected to supply ~1.6 M units in 2027 via Foxconn / Quanta / Wistron / Inventec ODM channels.
- Full-year 2025 revenue crossed USD 1B on AI-server connector demand.
- Competes against Amphenol, TE Connectivity, Molex, FIT, BizLink.
TSMC CoWoS-L Capacity Allocation
Rubin GPU uses TSMC's 9.5-reticle CoWoS-L package; COUPE supports 12× HBM4/4E integration from 2027.
Analyst shipment projections: 800 K Rubin units in 2026 → 3.2 M in 2027 at ~USD 32K ASP → ~USD 102B platform sales in 2027.
Alternate Platform Configurations — HGX/DGX Rubin NVL8 & Vera CPU Rack
The bulk of this part is calibrated to VR NVL72, but two adjacent configurations broaden the silicon supplier set — most importantly by pulling Intel into the Rubin platform via the x86 host path.
(1) HGX/DGX Rubin NVL8 — x86 host path. 8-GPU server reference (vs the 72-GPU NVL72 rack).

- Host CPU: Intel (INTC) Xeon 6 (6700P-Series) — 2× per system.
- Host memory: 32× DDR5-6400 RDIMMs, up to 4 TB.
- GPU + HBM: unchanged from NVL72 — 8× Rubin GPUs, HBM4 from the same three-supplier pool (SK Hynix lead, Samsung, Micron).
- Networking + storage: ConnectX-9, BlueField-4, and Micron (MU) PCIe Gen 6 E1.S all carry over.
Why x86 / why Intel?
- Software incumbency. Porting AI frameworks, orchestration stacks, and legacy enterprise software to ARM (the Vera path) still has a real lift; x86 stacks ship today.
- Brownfield customer base. Enterprise data center, telco infrastructure, hyperscaler-legacy compute pools, and traditional HPC favor Xeon 6 for deployment stability, OEM validation, mature ecosystem, and predictable lead times.
- AMD scarcity at the edge. AMD (AMD) EPYC is technically equivalent on x86, but its high-core SKUs are mostly absorbed by hyperscaler internal allocations — so Intel is the default x86 SKU available at enterprise scale.
- CPU:GPU ratio shift. As inference and agentic AI pull the ratio from 1:8 toward 1:1, x86 incumbency gains value — especially for orchestration and control-plane CPUs sitting alongside GPUs.
(2) Vera CPU Rack — standalone. A separate rack of up to 256 Vera CPUs.

- Memory: SOCAMM2 only — LPCAMM2 is not used in any Nvidia system. Supplier mapping is the same as the NVL72 Vera socket (§ 1 Memory by Chip): SK Hynix 192 GB (Mass Production (MP) Apr 2026), Micron 192 GB (MP Mar 2026; 256 GB samples enabling 2 TB / CPU), Samsung (samples 2025 → MP early 2026).
- Confirmed customers: Oracle (ORCL), CoreWeave (CRWV), Nebius (NBIS), Alibaba (BABA) — the greenfield AI-native segment that has already moved past x86 dependency.
- Adjacent rack: the Groq 3 LPX rack — deployed alongside Vera CPU racks in some inference fleets — draws 12 TB DDR5 per rack from Micron (MU), on top of its SRAM-only LP30 dies.
Configuration-level cheat sheet:
- VR NVL72 — 72-GPU flagship rack; Vera CPU (ARM Olympus) host; NVLink 6 scale-up; primary focus of this part.
- HGX/DGX Rubin NVL8 — 8-GPU server; Intel Xeon 6 host; brownfield x86 enterprise / telco / HPC customers.
- Vera CPU Rack — standalone CPU rack; 256 Vera CPUs; greenfield AI-native hyperscaler workloads.
- Groq 3 LPX rack — 256-LPU SRAM-only rack for decode / prefill workloads (replaces the cancelled Rubin CPX).
2. Substrate, PCB & CCL
Context: The cableless midplane design (Vera Rubin Decoded — Part 4 § 3) forces PCIe Gen6 to travel ~500 mm of PCB trace, which requires upgraded PCB materials (M8+ CCL, HVLP4 copper foil, possibly Quartz cloth). PCB area grows ~2.3× vs GB300.
CCL (Copper-Clad Laminate)
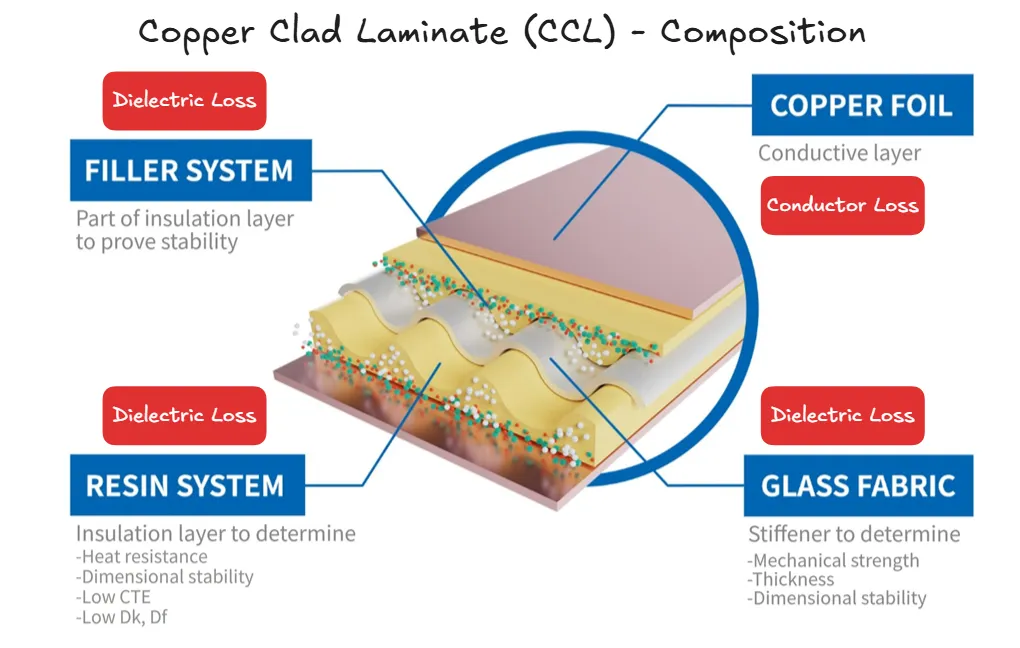
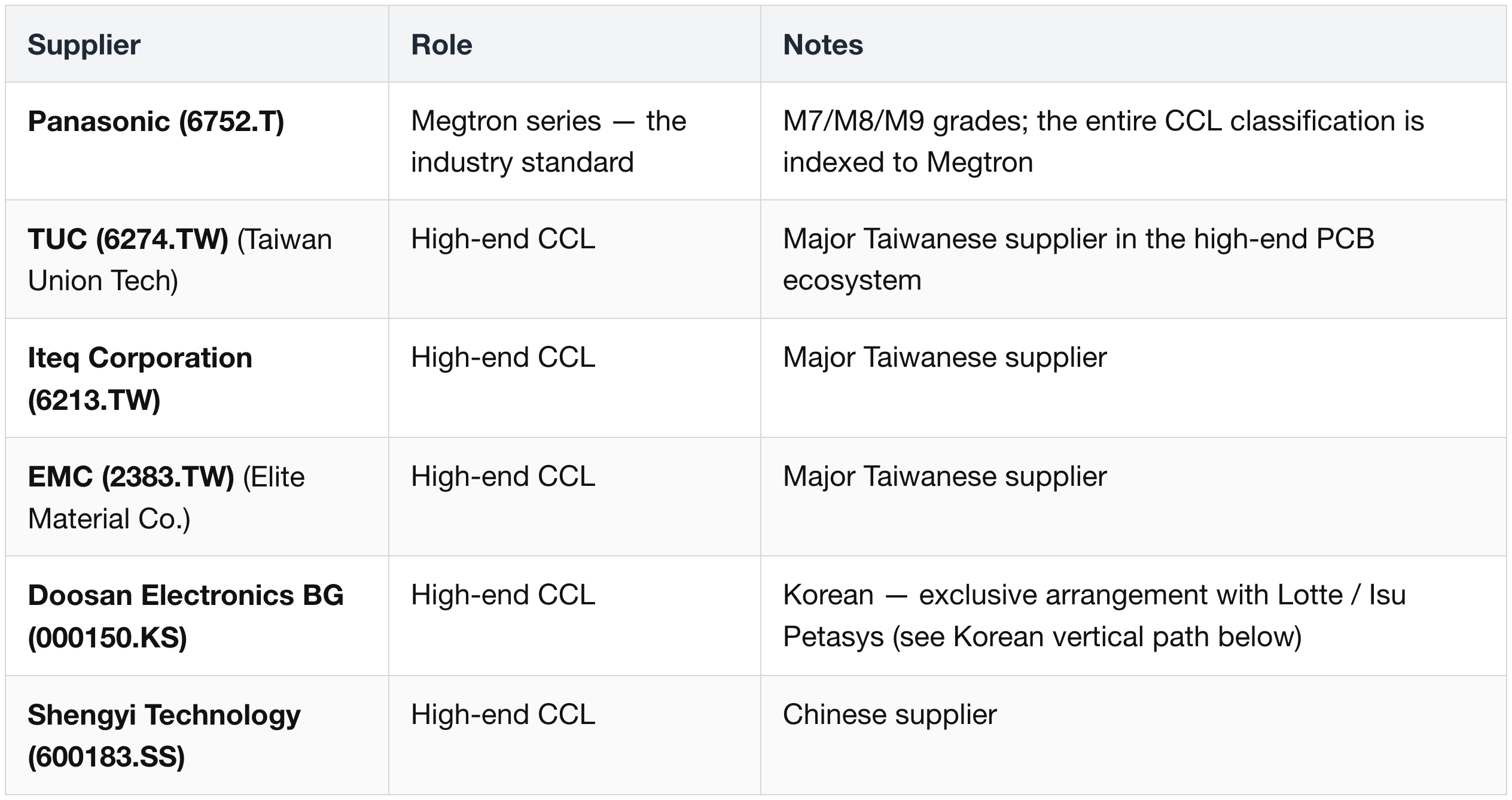
Copper Foil

PCB Fabrication
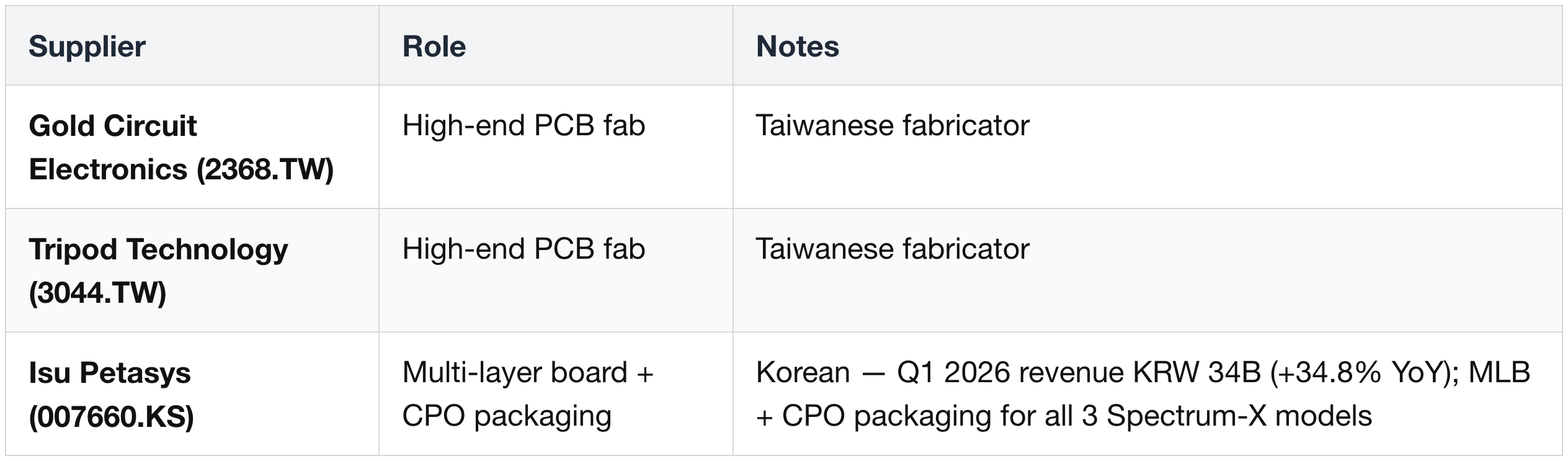
Package Substrate

Korean Vertically Integrated Path (Exclusive on Rubin)
A single-pipeline arrangement covers most North American computing-tray CCL for Rubin. This is a structural upgrade from Blackwell, where Doosan split CCL orders with Taiwanese competitors:

Scope of the exclusivity:
- Doosan near-exclusive on next-gen M8 / M9 grades for Rubin.
- R200 (Vera Rubin GPU) specifically shares CCL with ShengYi (600183.SS).
- B200 / GB200 / GB300 / GP100 remain Doosan-exclusive.
Customer concentration (Q1 2026):
- Doosan Nvidia sales hit record KRW 250B.
- Isu Petasys Customer A (likely Nvidia) = 42.2% of Q1 2026 revenue.
3. Liquid Cooling
Context:
- VR NVL72 is 100% liquid-cooled (vs 85/15 hybrid on GB200/GB300).
- Cooling stack: cold plates, manifolds, quick disconnects (UQD8 v2 standard), CDUs, pumps.
- Inlet up to 45 °C ("warm-water").
- Chiller-less designs become feasible.
Cold Plates
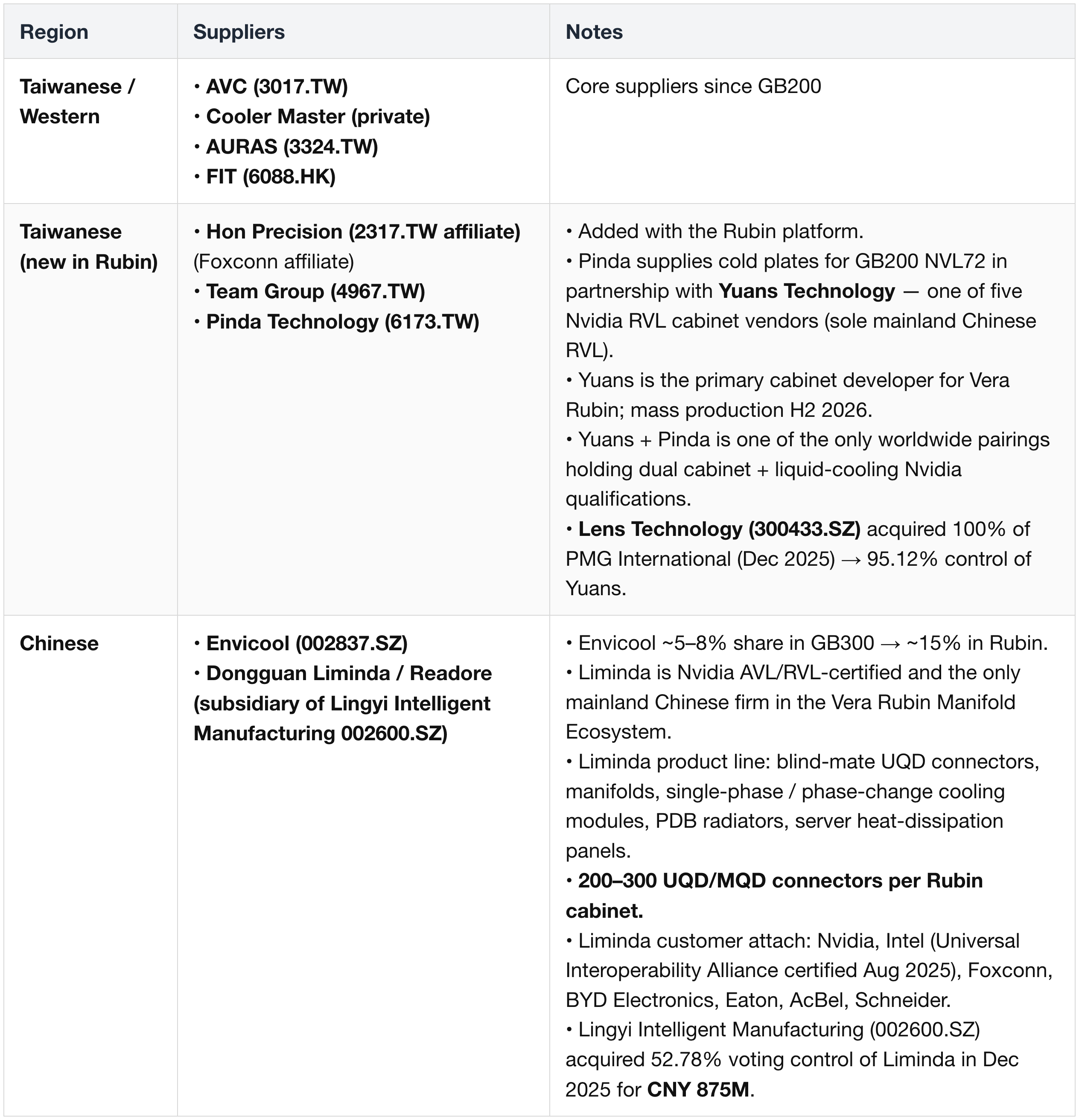
Quick Disconnects (UQD8 v2 standard)

Material upgrade trajectory: rigid plastic → metal as flow velocity / pressure rise; ~20% cost increase per QD.
CDU, Pumps, Valves & Heat Exchangers
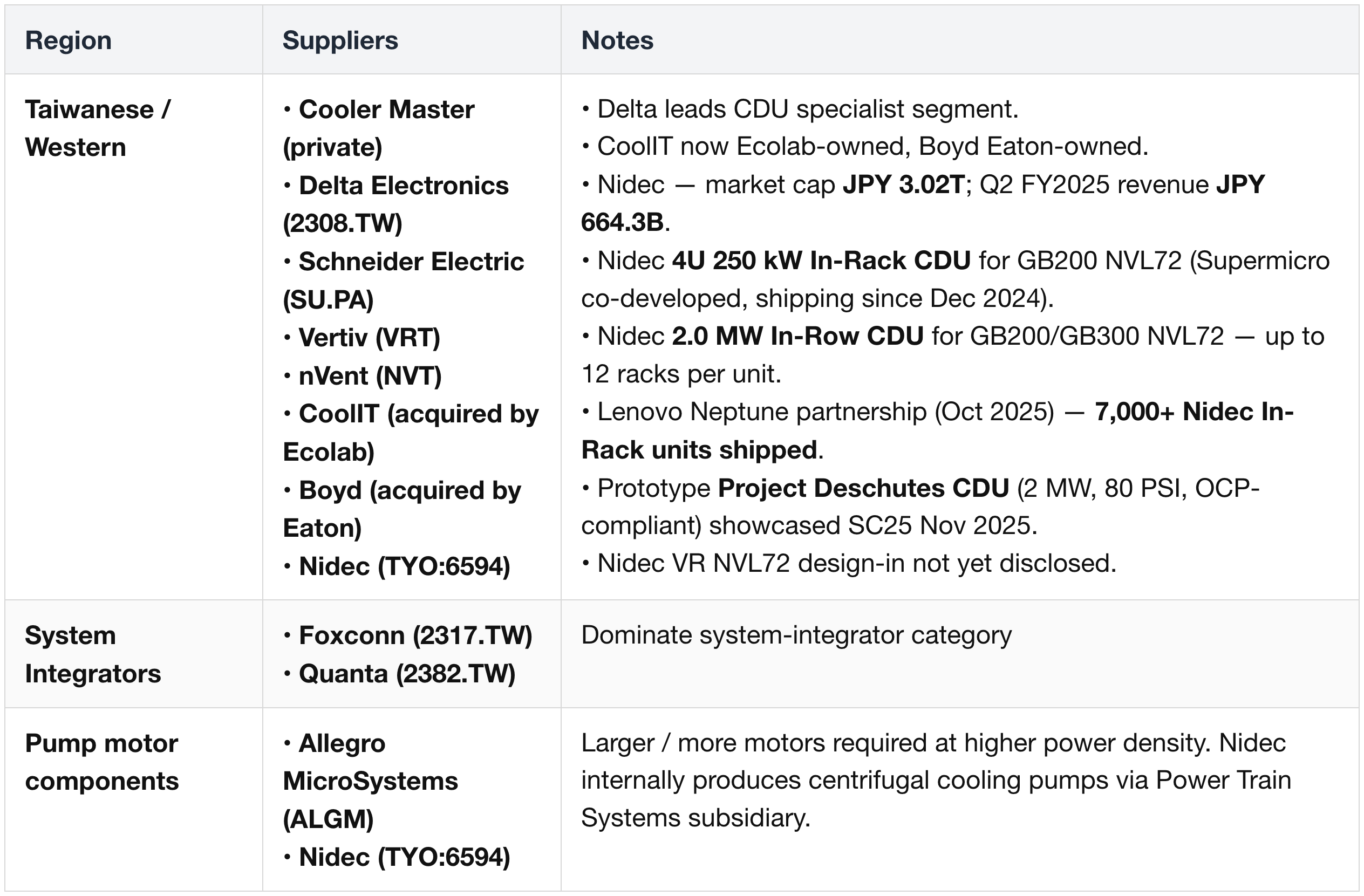
Facility-side Cooling (Dry coolers & chillers)

Reference deployments cited as proof-of-concept:
- Supermicro (SMCI) DLC-2 — >40 °C inlet on Blackwell already
- Lenovo (992.HK) Neptune — fully liquid-cooled at 45 °C (OCP Summit 2025)
- HPE (HPE) — industrial liquid cooling (2024 announcement)
- Firmus (private) — chiller-less GB200 deployment in production
- Schneider Electric RD111 — dual-loop architecture reference for GB300
Company Roll-Up
- AVC (3017.TW) (TW) — cold plates; core since GB200
- AURAS (3324.TW) (TW) — cold plates + QDs
- Cooler Master (private) (TW) — cold plates, CDU, core components
- FIT (6088.HK) (TW) — cold plates
- Foxconn / Hon Hai (2317.TW) (TW) — QDs + system integration
- Hon Precision (2317.TW affiliate) (TW, Foxconn affiliate) — cold plates, new in Rubin
- Team Group (4967.TW) (TW) — cold plates, new in Rubin
- CPC (Dover Corp, DOV) (US/EU) — QDs
- Envicool (002837.SZ) (CN) — cold plates + QDs; also in Google supply chain (custom-developed Deschutes 5 CDU)
Envicool positioning:
- Listed in Nvidia MGX ecosystem partner directory but not in any of Nvidia's three direct-supply tiers (AVL, RVL, NPN).
- Headline share trajectory: 5–8% (GB300) → 15% (Rubin) — based on industry consensus rather than vendor disclosure.
4. Rack-Level Power Delivery
Context:
- Per-rack TDP rises to 180–220 kW (vs 120–140 kW for GB200/GB300), trending toward 1 MW per rack in the next 2 generations.
- Reference design = 4× 110 kW shelves @ 50 V busbar.
- HVDC (800 VDC) variants for hyperscalers.
- BBU (Battery Backup Unit) / CBU (Capacitor Backup Unit) integration for grid stability.
AC/DC Power Conversion (Reference Design — 50 V Busbar)
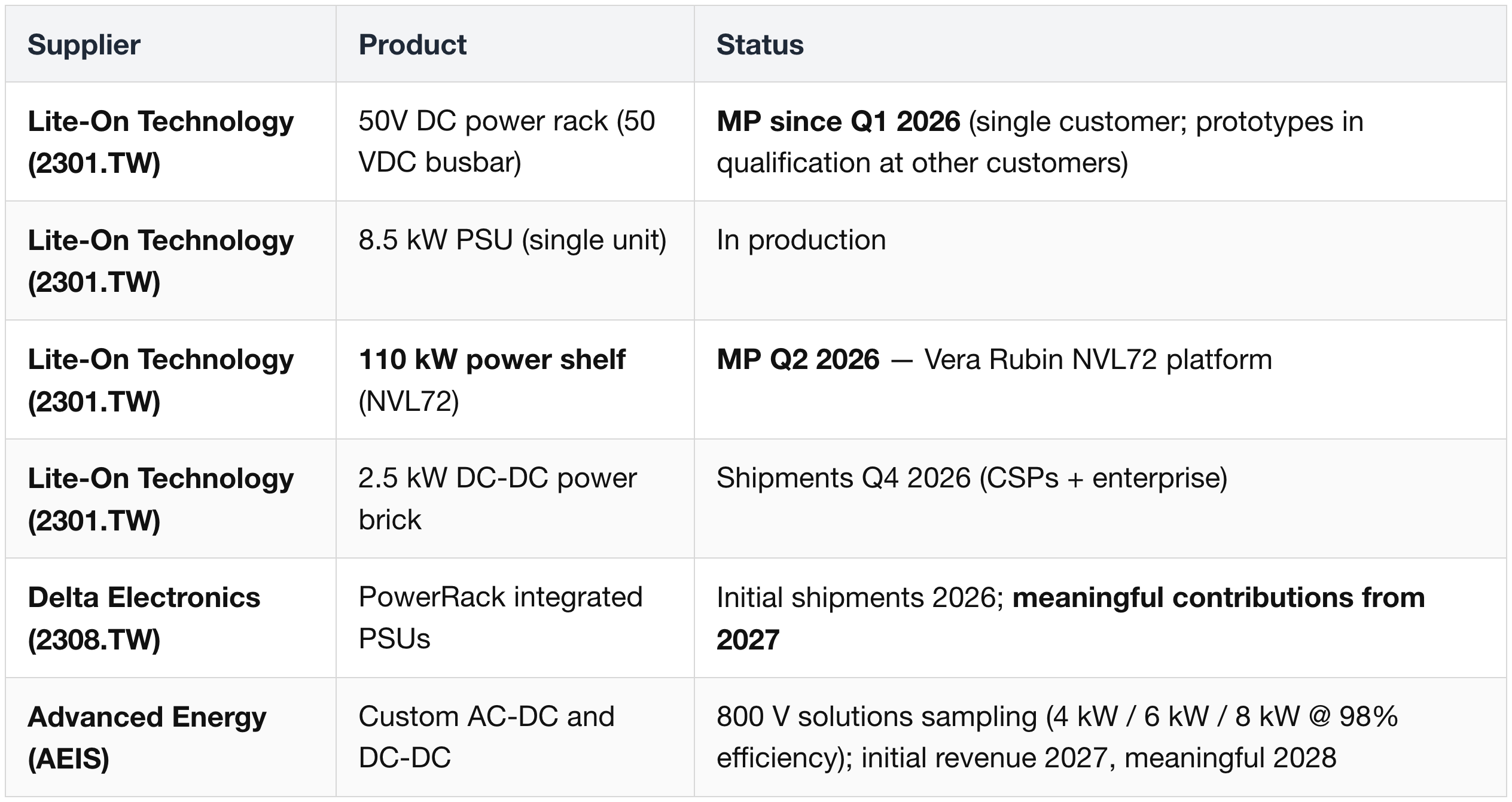
HVDC (800 VDC) Power Racks — Hyperscaler Variants
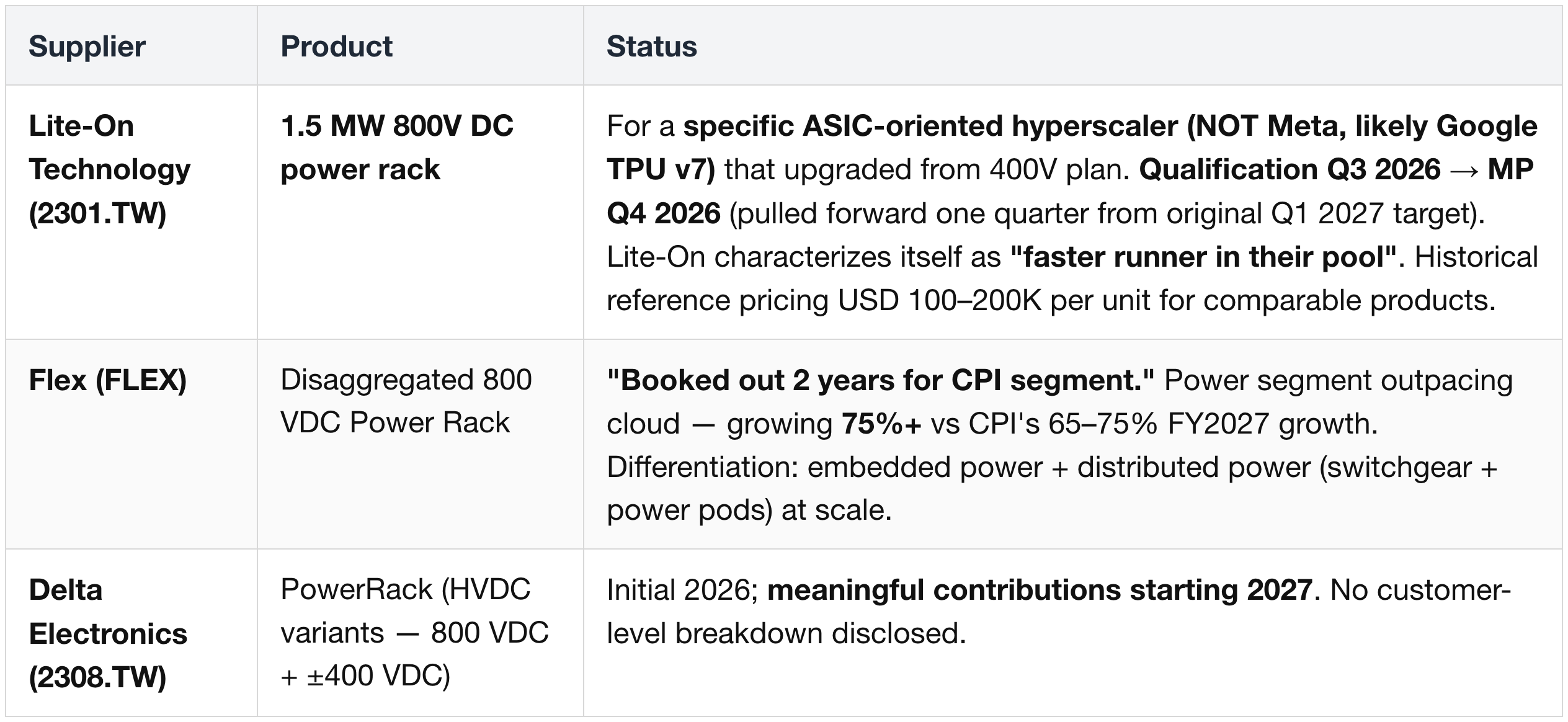
Lite-On (2301.TW) 1.5 MW 800V DC rack — customer fit:
- Google (GOOGL) TPU v7 is the lead candidate. (1) The pull-forward from Q1 2027 → Q4 2026 production aligns with Google's TPU v7 deployment cadence; (2) the 1.5 MW single-rack power band fits dense ASIC clusters more cleanly than typical GPU configurations (180-220kW). (3) Lite-On's GTC 2026 product showcase focused on Vera Rubin (GPU side) with QCT (Quanta Cloud Technology), separating the 800V customer from GPU-centric hyperscalers.
- AWS (AMZN) Trainium 3 is the secondary fit; ASIC nature aligns but the timing pattern favors Google.
- Excluded: Meta (META), Microsoft Azure (MSFT).
Battery Backup Units (BBU) + Capacitor Backup Units (CBU)
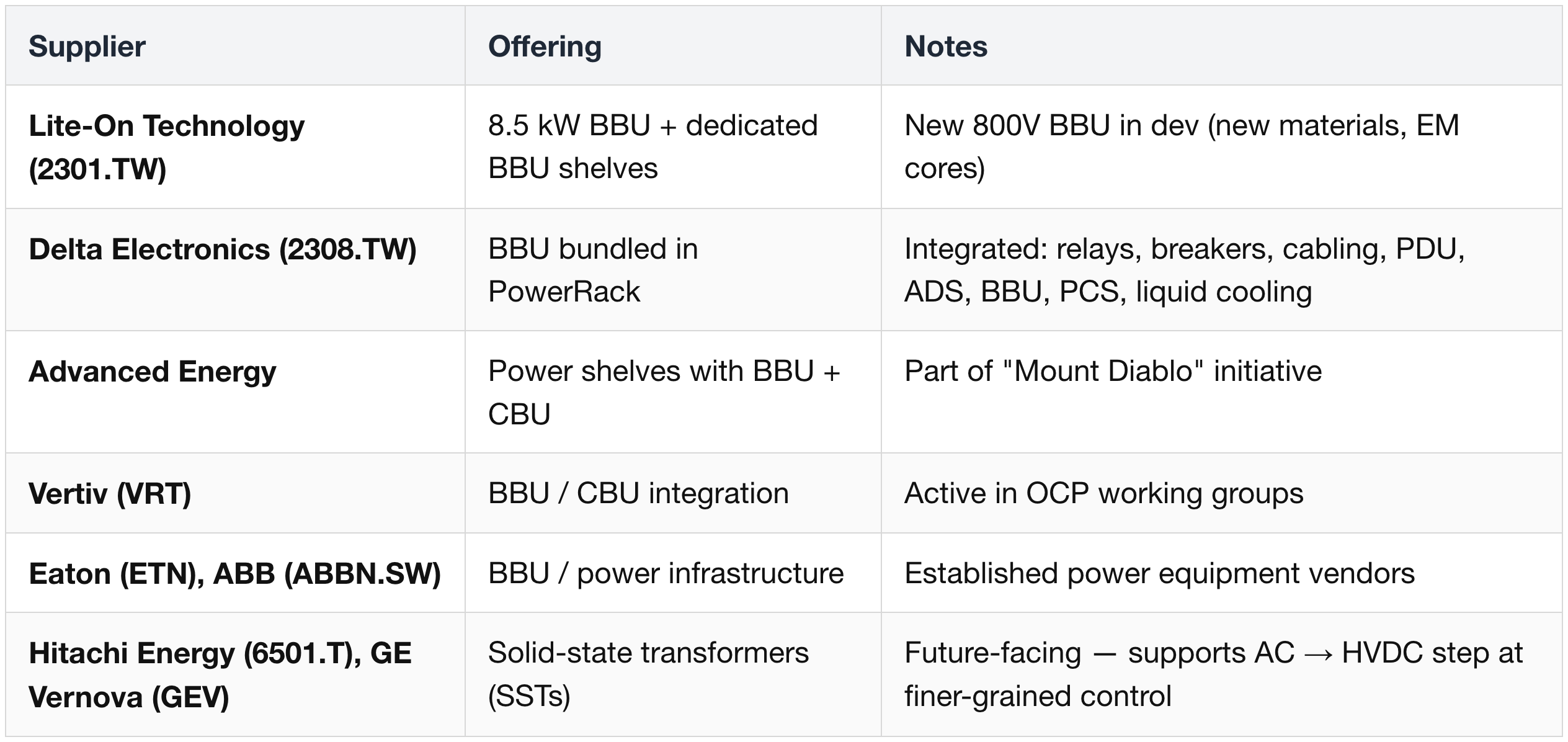
System Integration & Architecture Partners
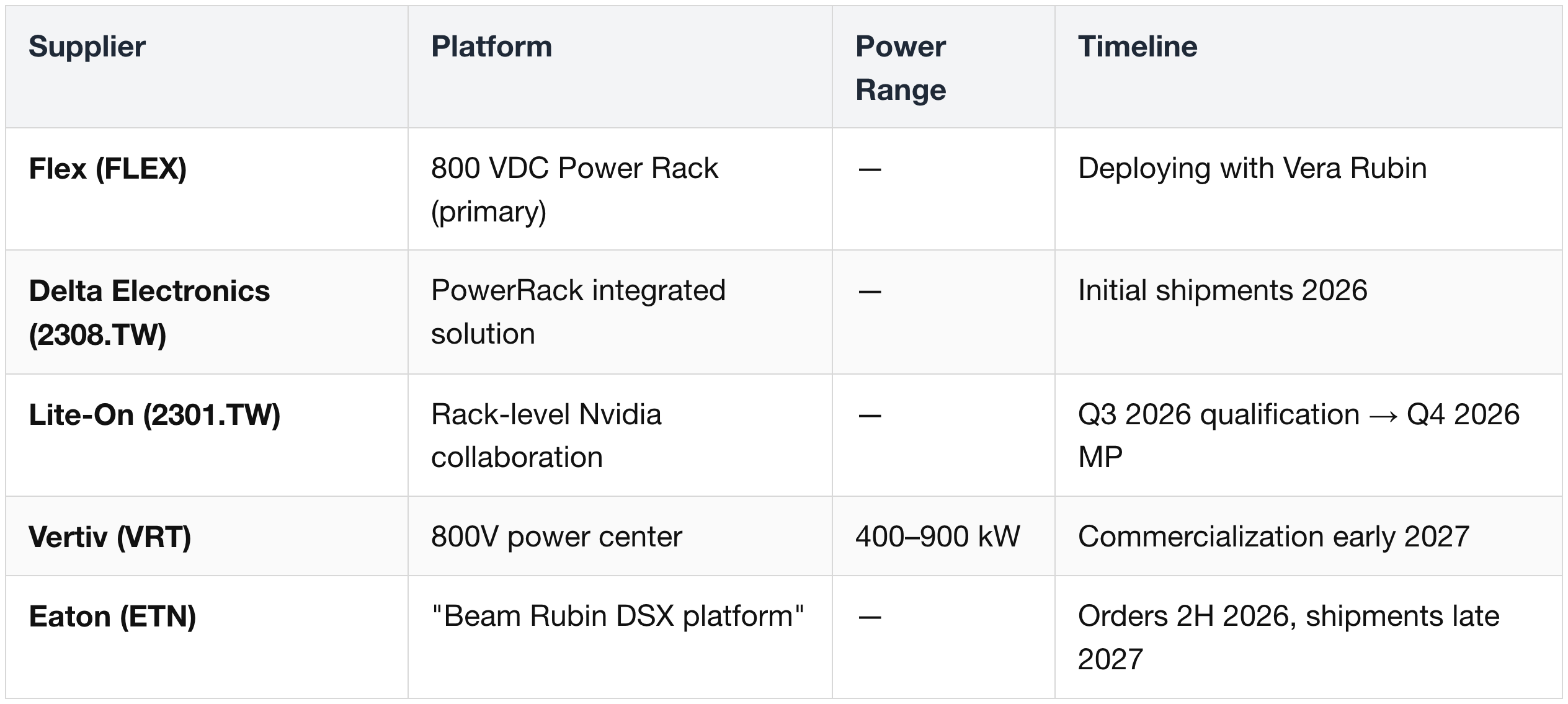
Architecture shift summary: rack-scale disaggregated 800V DC; primary rack-level partners are Delta Electronics (2308.TW), Flex (FLEX), Lite-On (2301.TW).
Liquid-Cooled Busbar Connectors

BBU / CBU Sizing — Nvidia MGX Spec
MGX (Modular GPU Accelerated server design) defines
- 400 J / GPU (6× prior gen)
- Intelligent Power Smoothing (peak current −25%).
- Per VR NVL72 rack = 28.8 kJ total (72 × 400 J). BBU vs CBU split is vendor / customer integration choice — Meta (META) deploys both, ratio undisclosed.
- Lite-On (2301.TW) confirmed Meta BBU supplier; "demand still exceeds supply" despite ~2× Kaohsiung capacity expansion.
Last-Inch 48V Vertical Power Delivery
Vicor (VICR)
- Characterized in Infineon Q1 2026 materials as the "gold standard" for 48V-to-sub-1V conversion at the AI rack last-inch.
- Completed qualification for Nvidia's next-gen platform in H2 2025.
- Direct competitive overlap with STM, Infineon, ADI, MPS, Monolithic Power Systems.
Nvidia 800V Power Alliance — Additional Partner Pool Note
Lead Wealth (private)
- Beyond Lite-On / Delta / Flex / Vertiv / Advanced Energy / Eaton / Hitachi Energy / GE Vernova / Innoscience / STMicroelectronics / MegMeet (all listed above), Nvidia's 800V DC alliance partner directory names Lead Wealth as a power-system component / power-module provider.
- Platform coverage per directory: GB200 NVL72, GB300 NVL72, Vera Rubin, Kyber.
Power Semiconductors — Analog / PMIC / GaN
The power-conversion chain (AC mains → 800 VDC HVDC → 50 V busbar → 12 V → ~1 V) is anchored by analog and power-discrete silicon vendors. Three names supply into the AI compute power portfolio:

5. NVLink 6 — Scale-Up Interconnect
Context:
- Inside-rack scale-up fabric.
- 36 NVLink 6 Switch chips per VR NVL72 rack.
- ~5,000 copper cables on the backplane — same cable count as GB300; doubled bandwidth via bidirectional SerDes.
- All-to-all rail-optimized fabric across 72 GPUs.
Switch Silicon & Foundry

Connectivity Infrastructure
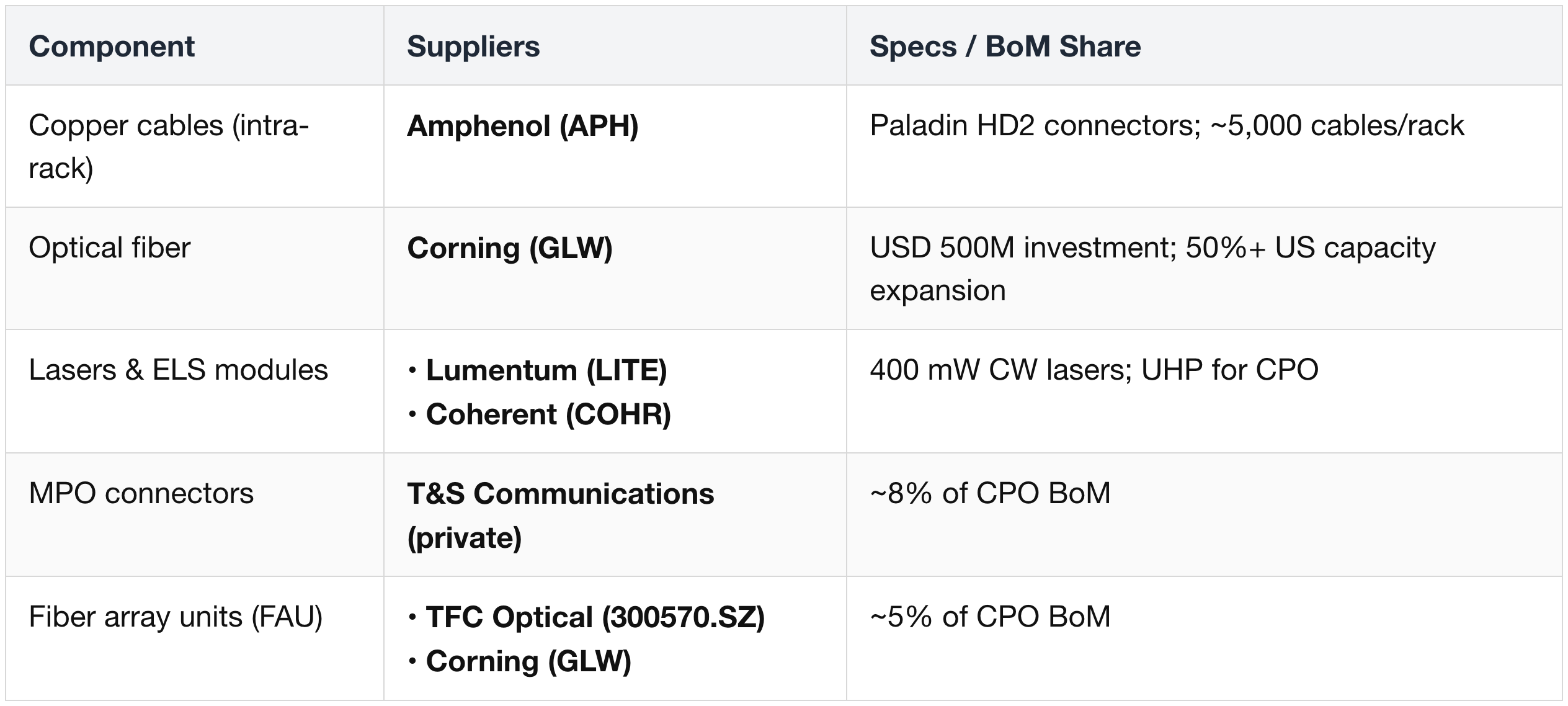
Optical Integration Partners (Strategic)
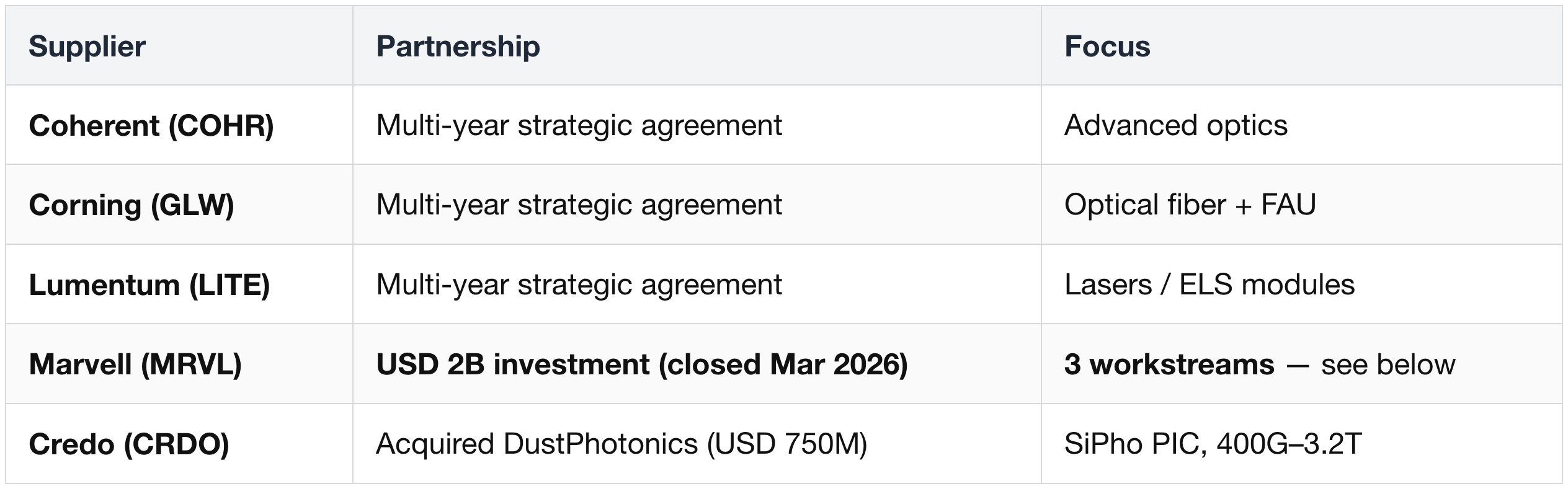
Marvell NVLink Fusion — USD 2B (closed Mar 31, 2026)
Equity structure
- USD 2B Nvidia equity investment closed March 31, 2026.
- Marvell's Concurrent Celestial AI acquisition closed February 2, 2026 at USD 3.25B (USD 1B cash + 27.2 M shares = USD 2.25B).
- Earn-out of up to 27.2 M additional shares contingent on cumulative revenue milestones:
- 1/3 payout if Celestial reaches USD 500M by Q4 FY29.
- Remainder if cumulative revenue exceeds USD 2B by Q4 FY29.
Three workstreams:
- NVLink Fusion IP for custom XPUs — embeds as IP block; bridges merchant Nvidia systems with in-house hyperscaler infra.
- AI-RAN silicon — Nvidia Aerial AI-RAN for 5G / 6G.
- Silicon Photonics — Celestial AI's Photonic Fabric for SiPho + CPO through 2028+, co-packaged into custom XPUs + scale-up switches.
Celestial revenue trajectory
- 2H FY28 initial contribution.
- USD 500M run-rate Q4 FY28 → USD 1B run-rate Q4 FY29.
- 16 Tb/s Photonic Fabric chiplets as the primary driver initially.
Named deployment candidates
- Amazon Trainium 4 — NVLink Fusion-compatible, lead customer for Celestial AI chiplets; large-scale CPO deployment CY27 (shipments late 2027, deployment 2028).
- Microsoft Maia-3 — BofA projects 4Q26 / 1Q27 launch, ~USD 600M CY28 revenue. Morgan Stanley more cautious: 60% custom-silicon CY27 growth vs mgmt's 100% target.
Marvell custom-silicon revenue outlook (Citi)
- Custom silicon: FY27E USD 1.8B (+20% YoY) → FY28E USD 3.6B+ (>100% YoY).
- XPU + XPU-attach: FY27E USD 3.0B → FY28E USD 4.2B.
- Total GAAP revenue (Morgan Stanley): FY27E USD 10.87B → FY28E USD 14.29B.
- BofA raised PT to USD 200 (from USD 125) May 13, 2026.
- Stock USD 196.33 May 22, 2026 — +131% YTD, +217% 1Y.
System Integration & Switch Assembly

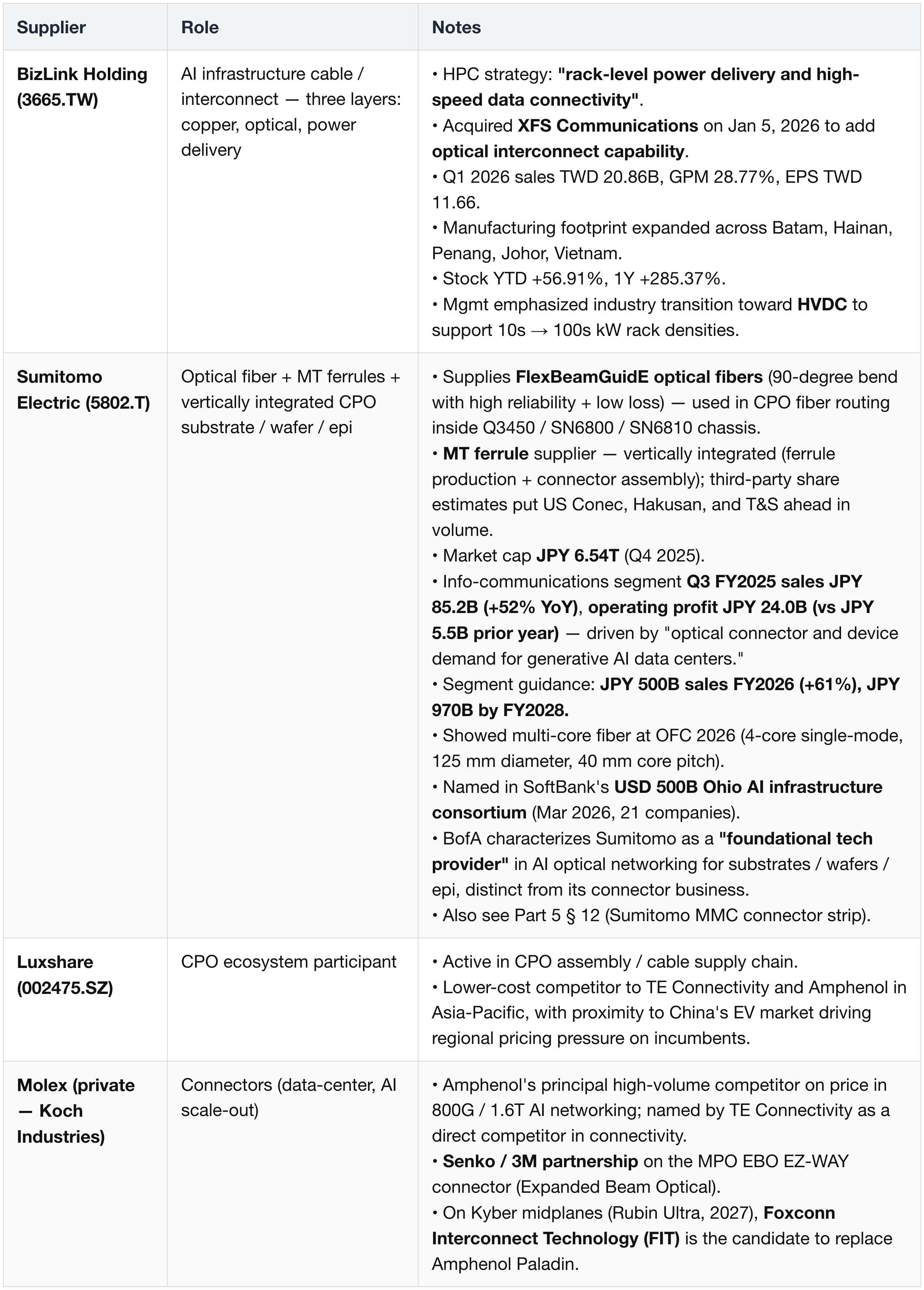
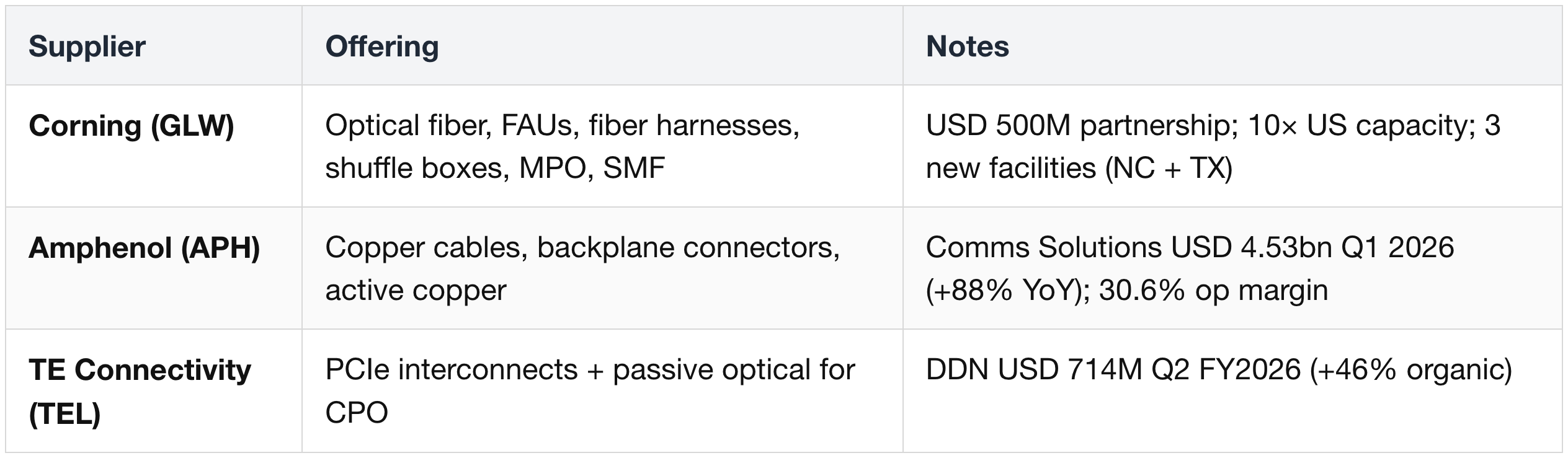
Additional Copper / Connector Suppliers
Additional copper-interconnect, cable, and connector vendors active across NVLink 6, PCIe Gen 6, and rack-internal interconnect supply.
6. PCIe 6.0 / Internal Interconnect
Context:
- PCIe Gen6 is the in-tray bridge between Strata (Vera + Rubin) and the front-of-tray modules (Orchid CX-9 NICs, BlueField-4).
- The ~500 mm midplane PCIe traces are the engineering driver for PCB material upgrades.
- Outside the tray, PCIe also appears in scale-up / scale-out adjacency (UALink, NVLink Fusion).
Retimers & Redrivers

Aries 6 share nuance:
- "97% → 80%" reflects revenue-mix shift, not share erosion.
- Aries grew +70% YoY in 2025; Scorpio (PCIe switch) ramped faster, shifting the mix.
- ASP uplift +20% per generation (Gen6 → Gen7 → UALink).
PCIe Switches
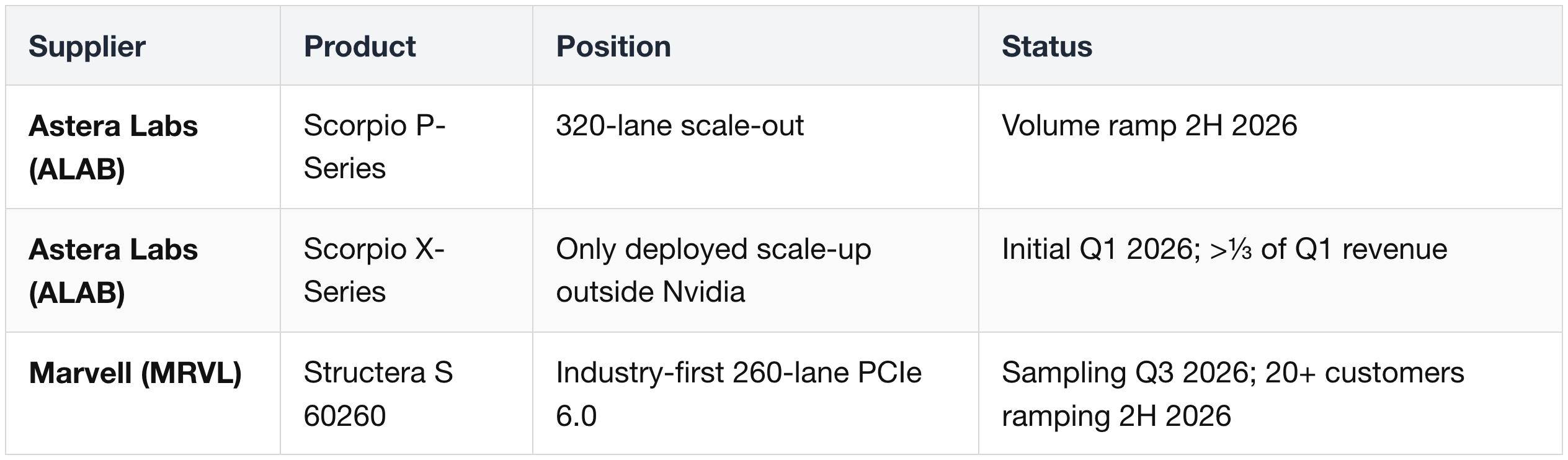
Connectors & Cables

SerDes IP & Silicon Foundry
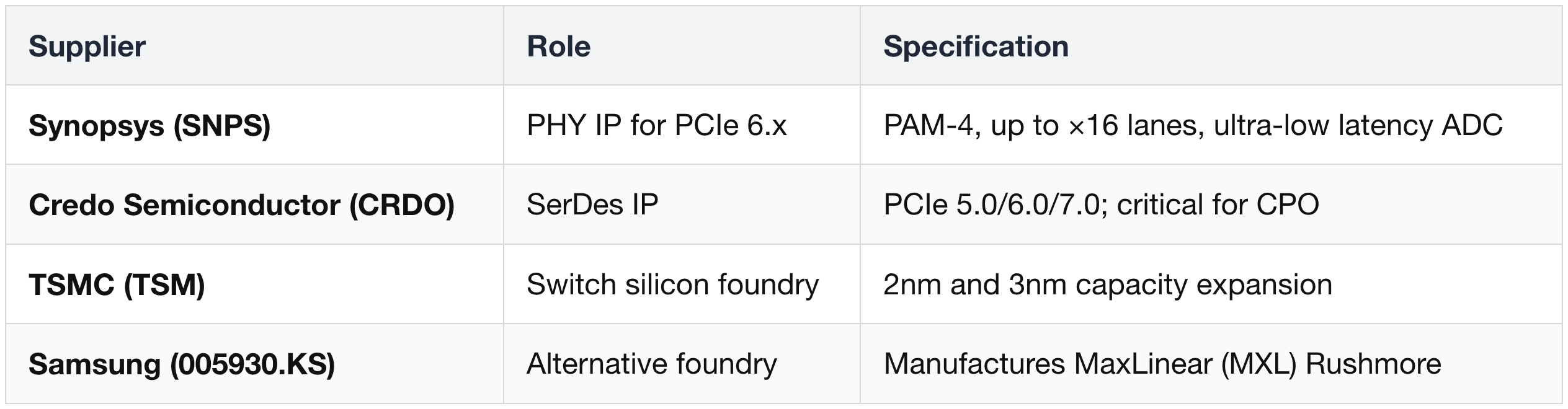
Active Electrical Cables (AECs)

AEC TAM: USD 1.2B (CY25) → USD 13.6B (CY30) — 62% CAGR confirmed. Driven by transition to 200G per lane (1.6T ports) + expanding rack densities.
NVLink Fusion & UALink (Adjacent Future)
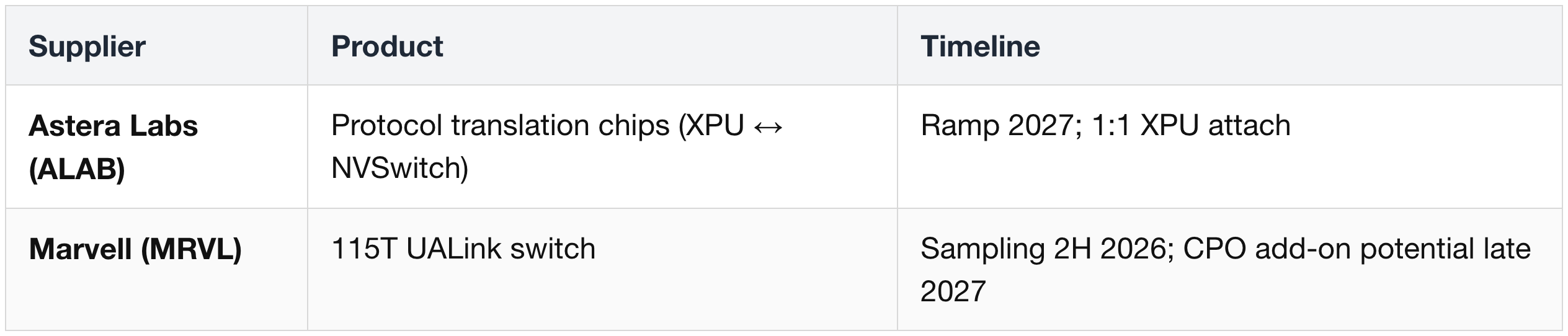
7. Quantum-X800 — InfiniBand Scale-Out
Context:
- Nvidia's InfiniBand AI networking platform.
- Two SKUs: Q3400 (pluggable optics) and Q3450 (CPO).
- Internally 4× Quantum-3 ASICs per box, 115.2 Tb/s aggregate, 144 × 800G ports.
- More popular with neoclouds than hyperscalers.
Q3400 Pluggable Variant

Q3450 CPO Variant

Strategic Partnerships
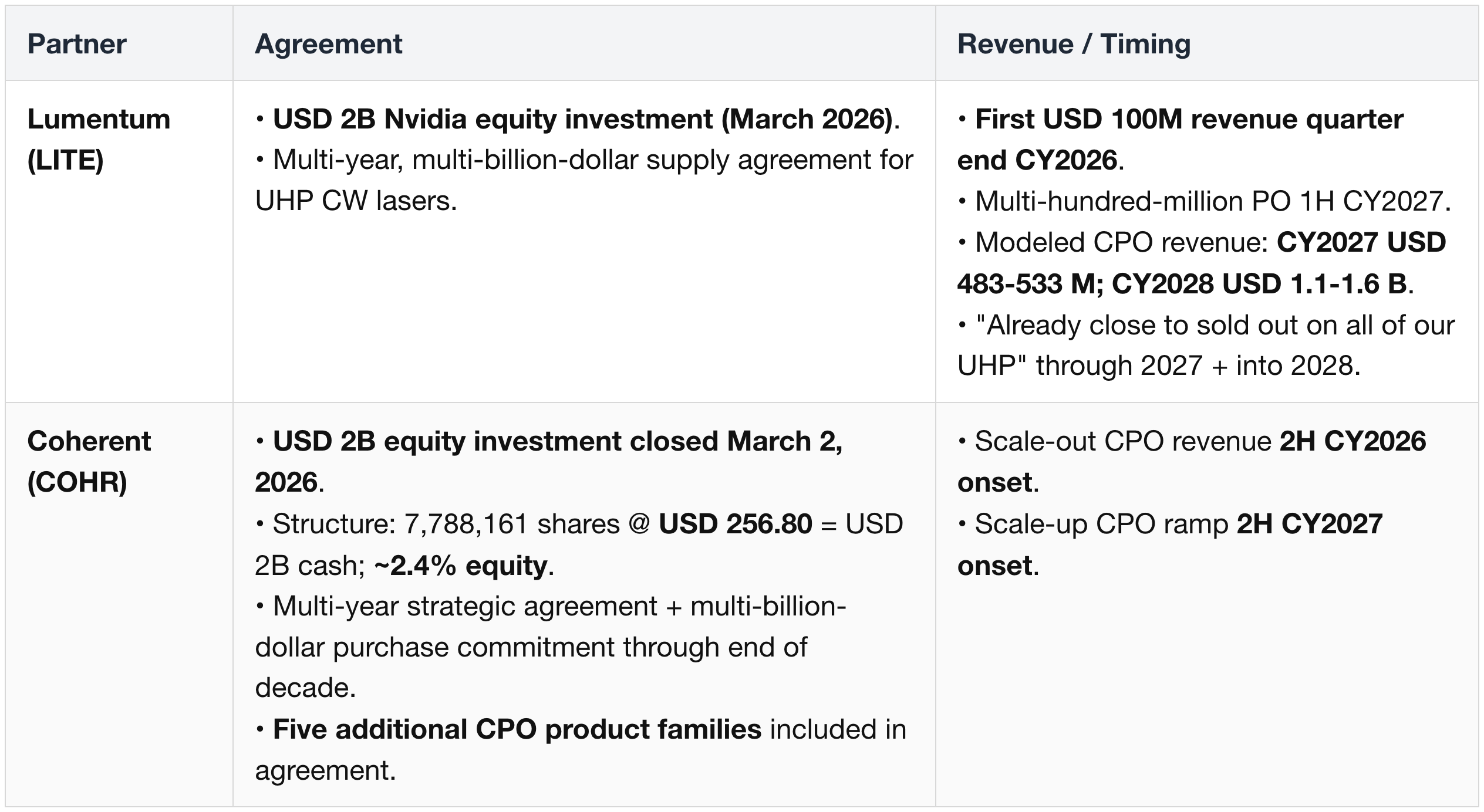
Shared Optics Infrastructure

Competitive Context (Alternative CPO Platforms)
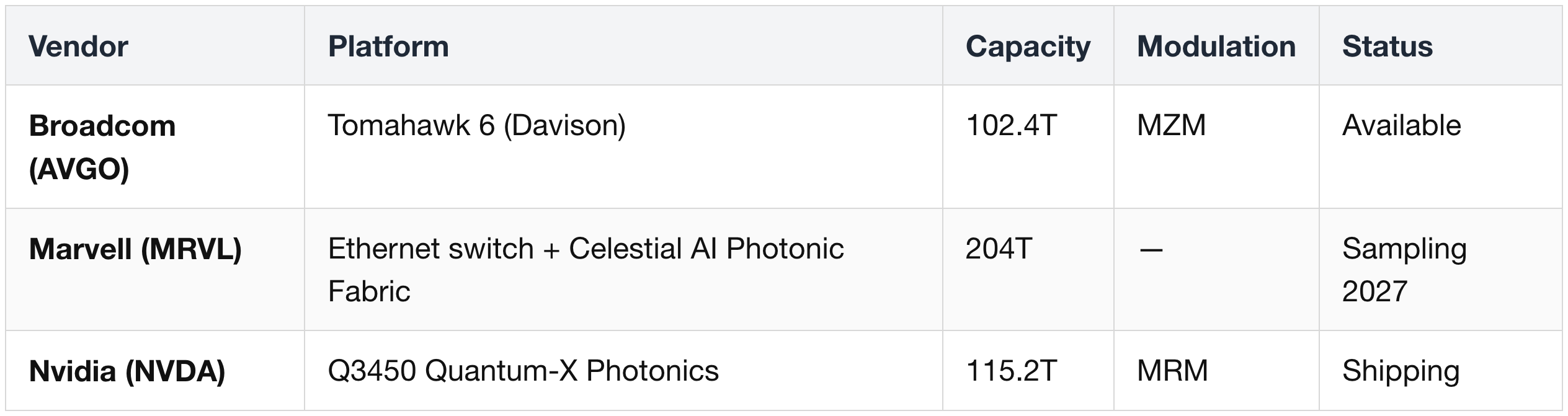
Q3450 CPO advantage: insertion loss ~4 dB vs ~22 dB for pluggables; 10× resiliency, 2× speed, 5× scalability.
8. Spectrum-X — Ethernet Scale-Out
Context:
- Nvidia's Ethernet AI networking platform (RoCE).
- Three SKUs in the SN6000-LD series:
- SN6600 — pluggable.
- SN6800 — CPO, 4-ASIC, 5RU.
- SN6810 — CPO, 1-ASIC, 2RU.
- Hyperscaler default.
- Spectrum-XGS extends to multi-site scale-across.
Switch ASIC & Foundry

CPO Optical Components
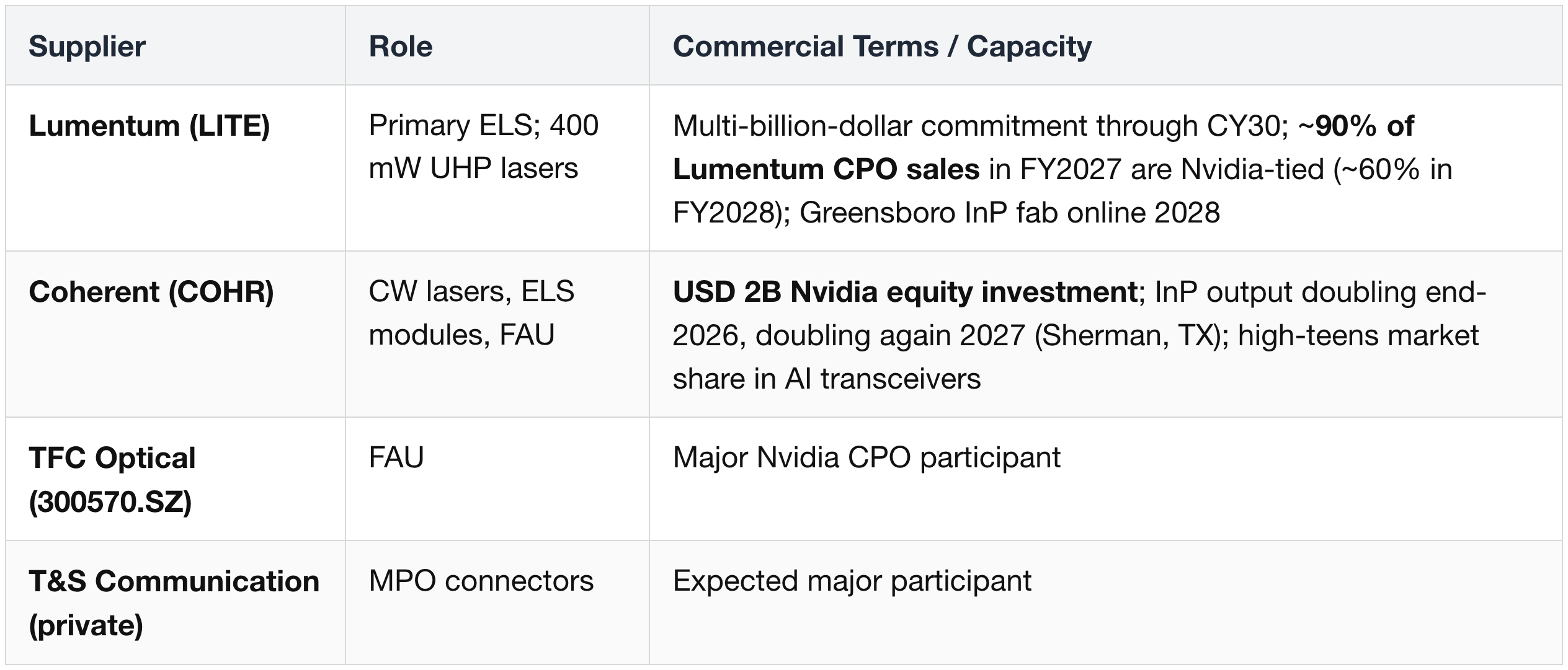
Spectrum-X CPO Ramp Curve (Stage 0 / 1 / 2)
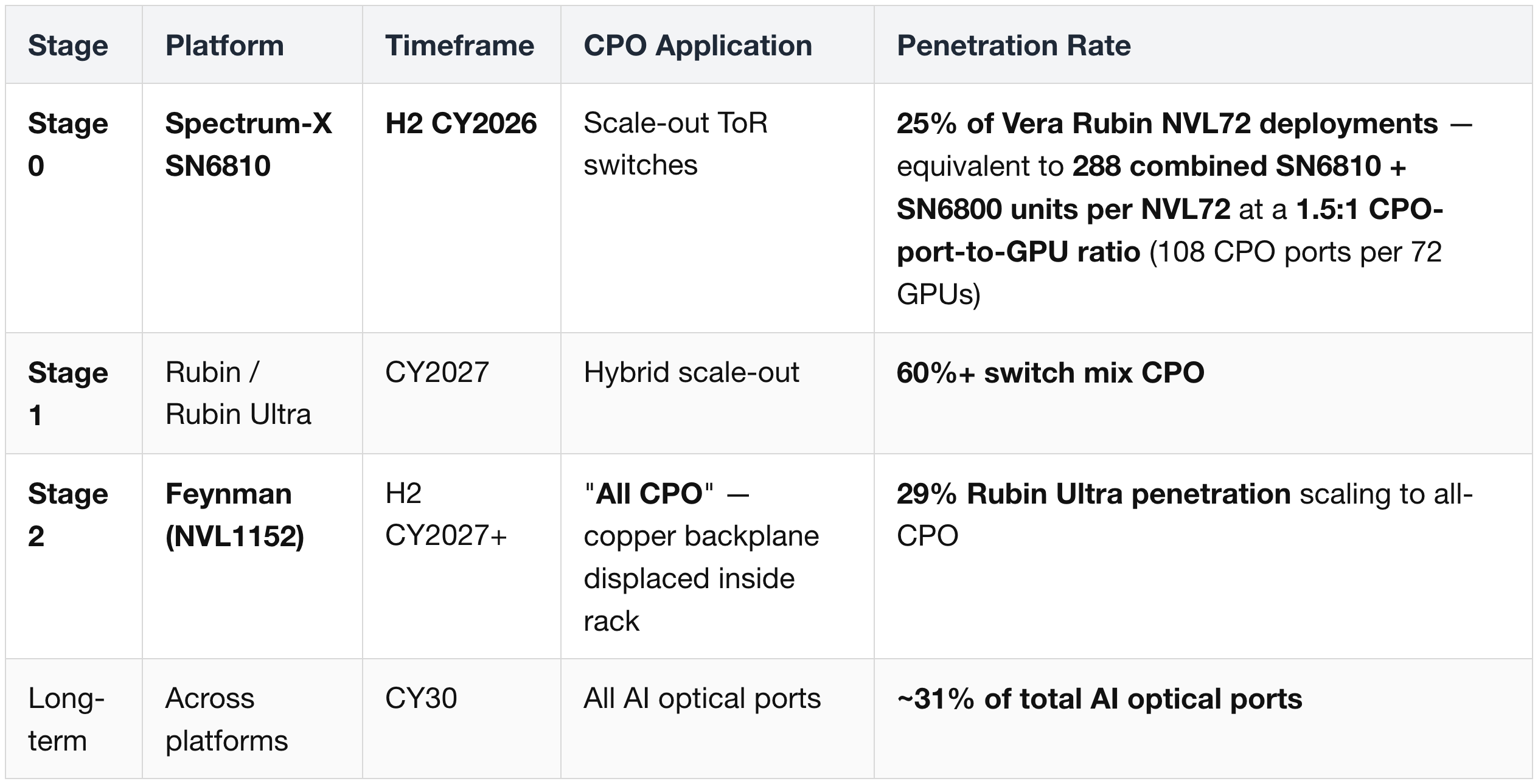
Pluggables remain dominant through 2030; CPO becomes material in 2028.
CPO Content per Rack — Form-Factor Driven
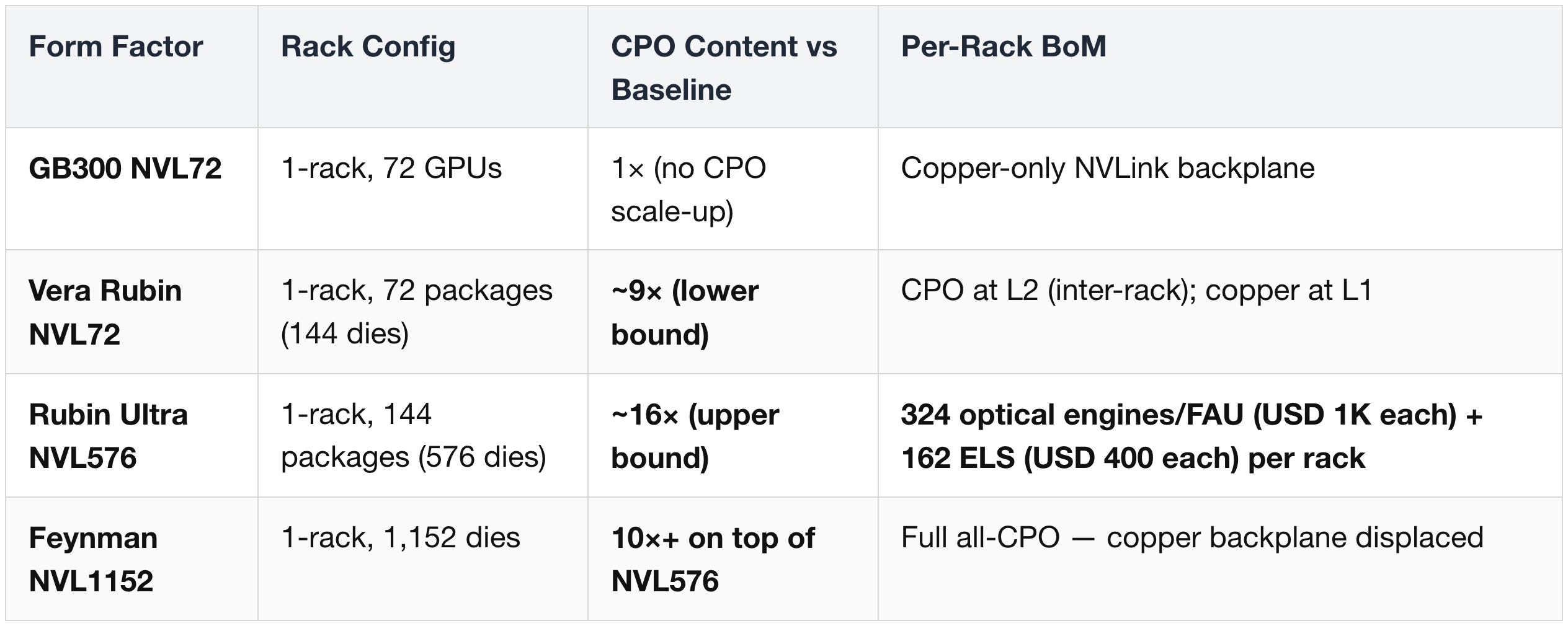
Networking-content scaling (GB300 NVL72 → NVL576):
- Scale-out content +16×, scale-up +45×.
- CPO TAM = USD 91B by 2028, 59% of USD 154B AI networking.
Coherent + Lumentum Revenue Exposure
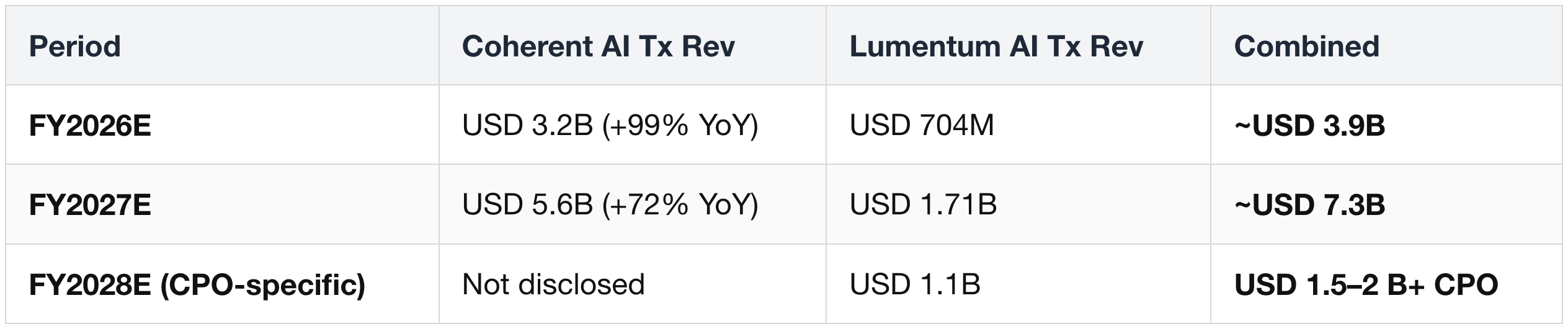
CPO-specific split:
- Lumentum (LITE) FY27E: USD 533M total CPO → ~90% Nvidia (USD 480M)
- Lumentum (LITE) FY28E: USD 1.1B total CPO → ~60% Nvidia (USD 660M)
- Coherent (COHR): CPO not disclosed; "material" only in H2 2027 as Rubin Ultra ramps
Why Lumentum leads near-term:
- Primary ELS supplier with a 15-month qualification lead.
- Already shipping for Quantum-2 InfiniBand.
Coherent's catch-up:
- 6-inch InP (4× products per wafer at <½ the cost vs 3-inch).
- Capacity doubling by end-CY26, doubling again end-CY27.
Nvidia's USD 4B dual investment (~USD 2B each, Mar 2026) = intentional dual-sourcing.
PCBs & Packaging

System Assembly (ODMs)
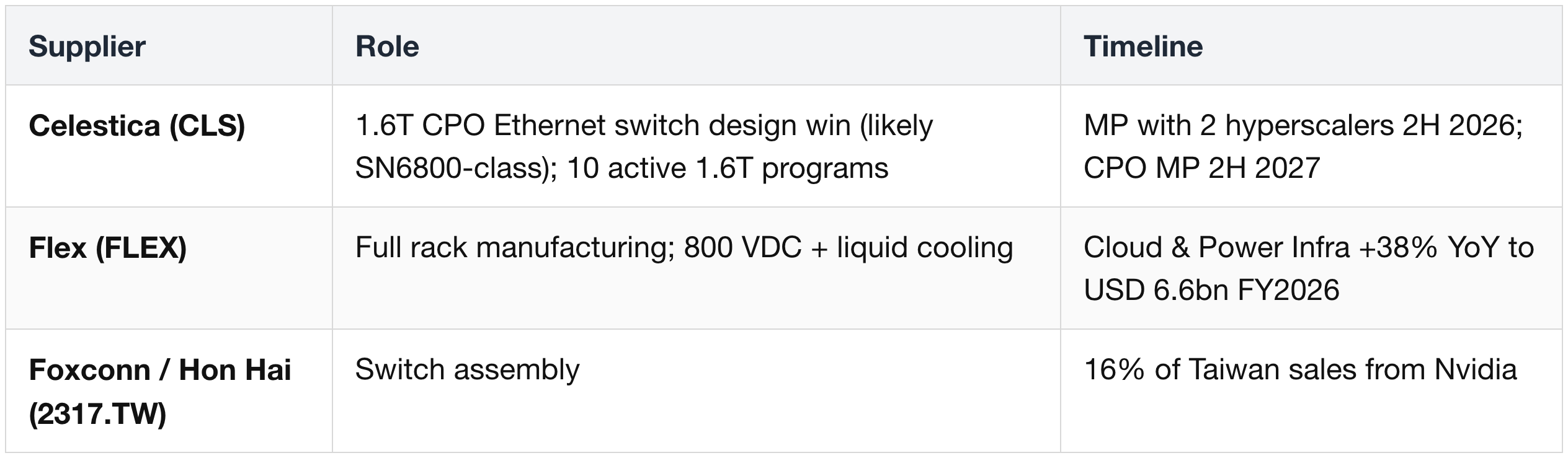
Fiber & Connectivity
Non-Nvidia Ethernet Alternatives (Competitive Reference)

Hyperscaler Vera Rubin Scale-Out — Confirmed Commitments
Public Vera Rubin NVL72 commitments by hyperscaler (rack-level scale-out specifics remain under NDA):
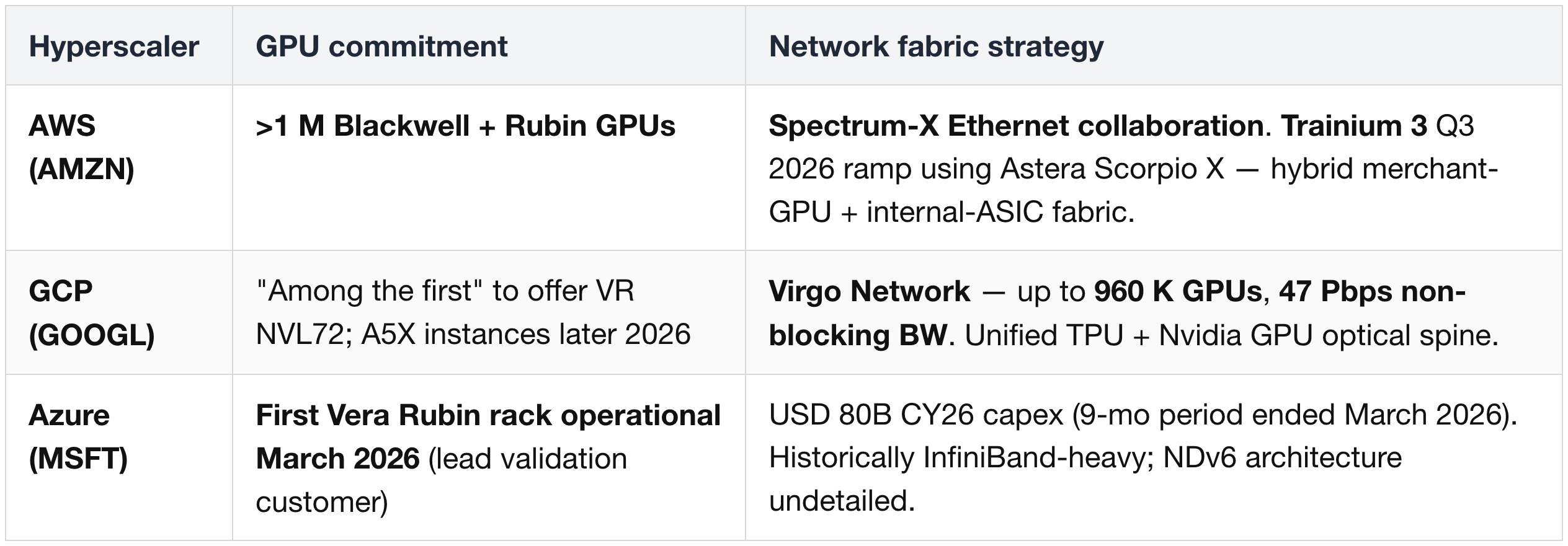
AWS Trainium = additive, not displacement (supplier-relevant):
- AWS doubling compute capacity to 24 GW by 2027 = USD 100B+ Trainium + USD 38B+ Nvidia GPUs concurrent from H2 2026.
- Astera Labs content per Trainium 3 unit reaches USD 600+ by end-2026 (5× vs Trainium 2). Marvell NVLink Fusion extends to AWS Trainium (Q4 2026 design win) — bridges both ecosystems.
Memory (Switch-side)

Spectrum-X SN6000-LD Full Spec Table
All three SKUs are liquid-cooled (LD = "Liquid-DC") and built on the Spectrum-6 ASIC. Full per-SKU specifications:
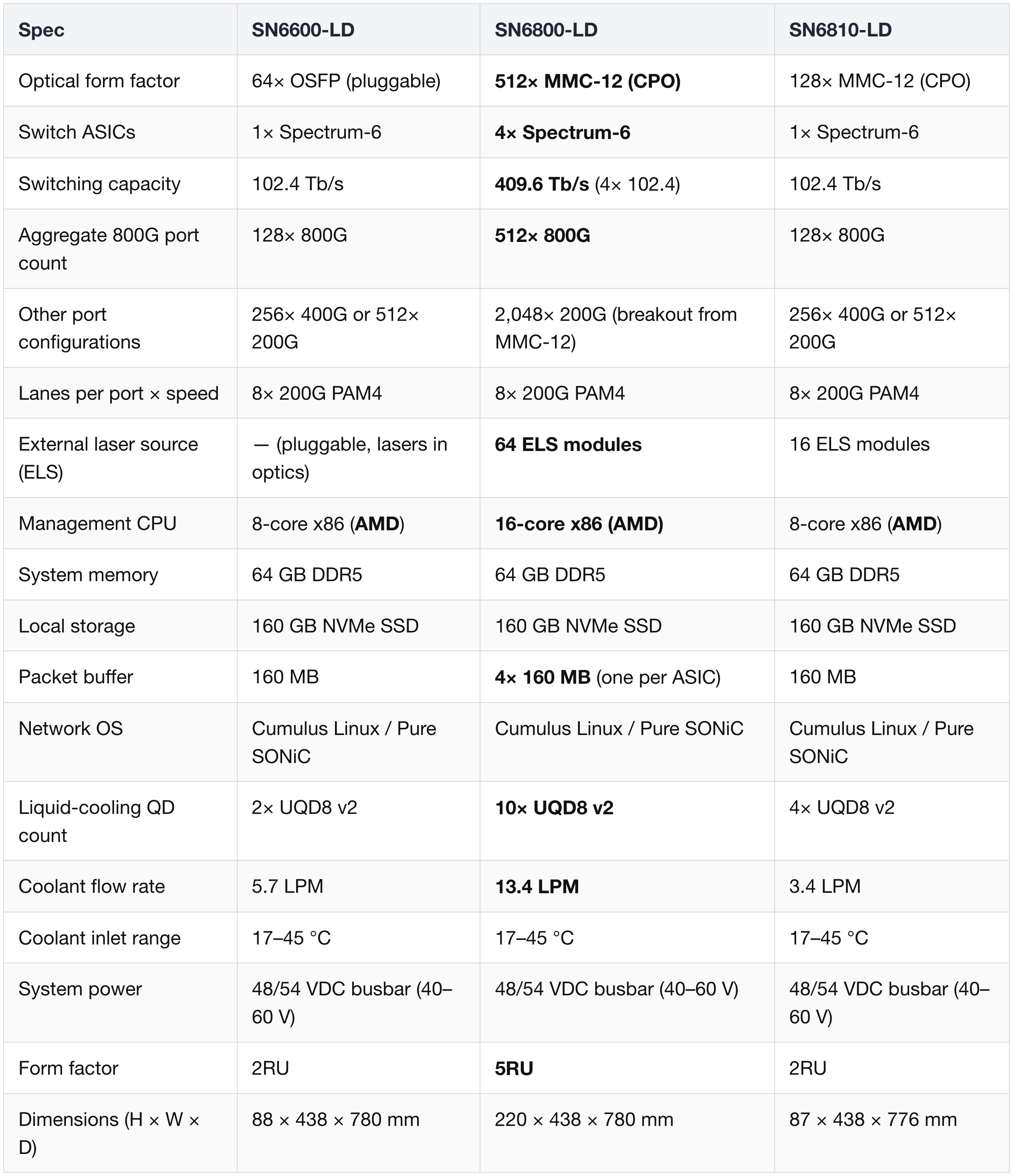
Reading the table:
- Pluggable vs CPO split — SN6600-LD uses OSFP cages with traditional pluggable transceivers (integrated lasers); SN6800-LD and SN6810-LD use MMC-12 connectors (12-fiber high-density) with external ELS modules.
- SN6800-LD is unique — the only 4-ASIC, 5RU SKU; 4× 160 MB packet buffer and 16-core CPU reflect that it's effectively four switches integrated into one box with an internal fiber shuffle.
- Same SerDes physics across all three — 8× 200G PAM4 per port. The differentiator is ASIC count and optical interface (CPO vs pluggable).
Cross-rack compatibility:
- Power — 48/54 VDC busbar with 40–60 V tolerance is compatible with the GPU rack's 50 V busbar.
- Cooling — 17–45 °C coolant inlet matches the rack warm-water envelope (Vera Rubin Decoded — Part 4 § 6); UQD8 v2 is the same QD standard used throughout the rack (CPC, Danfoss, Stäubli, Parker Hannifin as suppliers).
Simplified model-differentiation table (architecture, bandwidth, ports, CPO, cooling) lives in Vera Rubin Decoded — Part 5 § 13.
9. System Integration & Assembly
Context: L10 assembly is the final step where modules are placed into trays and trays into racks. The cableless design has dramatically reduced assembly time (from ~1.5h–2h to ~5 minutes per tray), simplifying the partner ecosystem.
L10 Assembly Partners (with automation capability for Rubin)

Explicit share allocations not publicly disclosed (NDA). Nvidia revenue exposure proxy: Wistron 16%, King Yuan Electronics (2449.TW) 36%, TSMC 19%.
Full-Rack System Integration
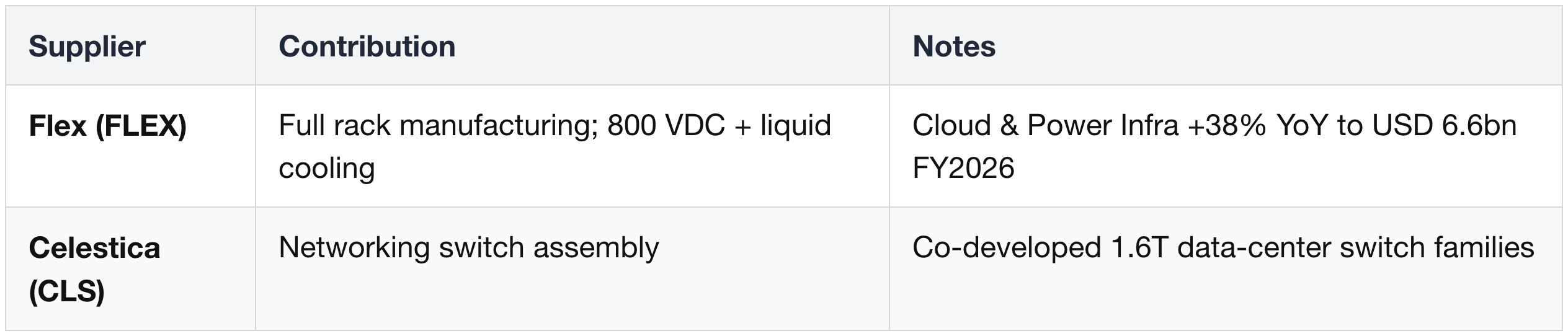
Compute Tray Module Suppliers (in addition to the above)
Within the tray itself, specific modules are sourced from:
- Strata Module (Vera + Rubin + SOCAMM) — Nvidia reference; assembled at L6 by Foxconn (2317.TW) / Quanta (2382.TW) / Wistron (3231.TW). SOCAMM2 sockets from Lotes (3533.TW) (§ 1).
- Orchid Module (CX-9 + OSFP + E1.S) — same L6 partners
- Midplane (PCB only) — see § 2 PCB suppliers (Isu Petasys (007660.KS), Unimicron (3037.TW), etc.)
- BlueField-4 Module — Nvidia DPU board; mostly customized by hyperscalers (see Vera Rubin Decoded — Part 5 § 14)
- System Management Module (SMM / TPM / DC-SCM) — hyperscaler-customized; AST2600 BMC from ASPEED (5274.TW) on the reference design
- Vera CPU Compute Tray mechanical — Yuan High-Tech Development (5474.TWO) confirmed as a tier-3 mechanical-housing supplier specifically for the Vera CPU Compute Tray. Also legacy capabilities in Nvidia GPUDirect-compatible video capture / I/O, and Nvidia Clara Holoscan MGX medical-AI device co-development.
Cabinet, Rail & Mechanical Sub-System Partners
Authorized server-cabinet, slide-rail, and mechanical sub-assembly partners for GB300 / VR NVL72 / Vera Rubin platforms:

10. Cross-Subsystem Heatmaps
Three at-a-glance views of the platform — what each chip is (architecture / ISA), what memory it uses, and which suppliers it pulls from. Full per-row detail and supplier-specific commentary live in §§ 1–9; this section is the cross-reference layer.
(1) Chip Architecture / ISA
Rows = chips in the platform; columns = ISA / architecture families + foundry. Same data structured for at-a-glance scanning (full annotated table in § 1).
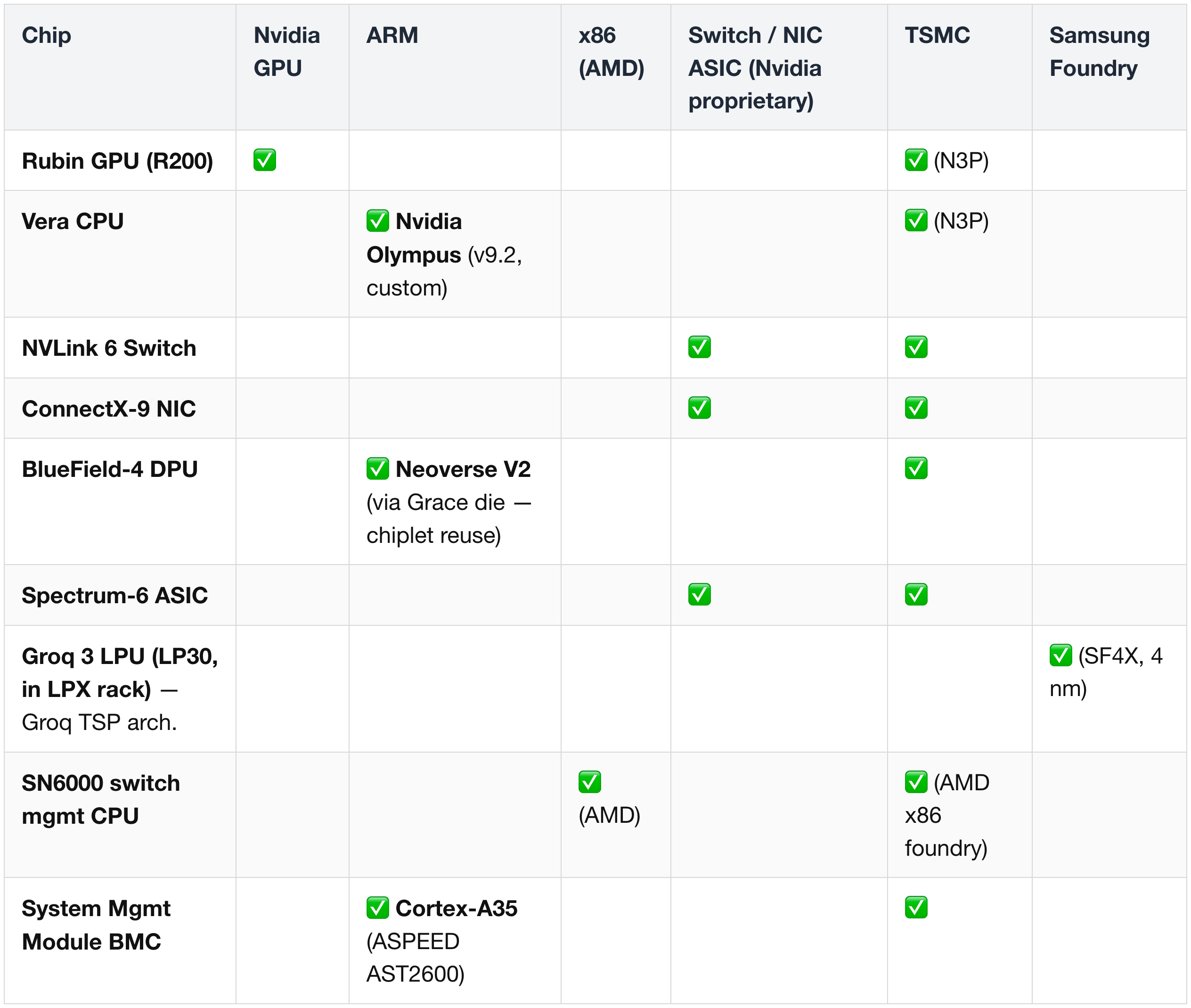
Key readouts:
- Nvidia GPU lineage — Rubin GPU only. One row in the heatmap, but the highest dollar concentration on the platform.
- ARM — three different flavors in the rack: Nvidia's custom Olympus (Vera), 3rd-party Neoverse V2 (BlueField-4 / Grace), and 3rd-party Cortex-A35 (BMC).
- x86 — single row, the AMD-based Spectrum-X switch management CPU.
- Foundry concentration — every Nvidia-designed chip + the AMD x86 management CPU + the ASPEED BMC ride TSMC. Samsung Foundry has one tenant in the rack: Groq's LP30 (SF4X 4 nm) and the LP35 refresh. LP40 moves back to TSMC N3P for Feynman 2028 — Samsung's slot in the platform may not survive into the next generation.
(2) Memory by Chip
Rows = chips / devices that carry memory; columns = memory type checkmarks + count + specs + supplier tiers. Full annotated narrative in § 1.
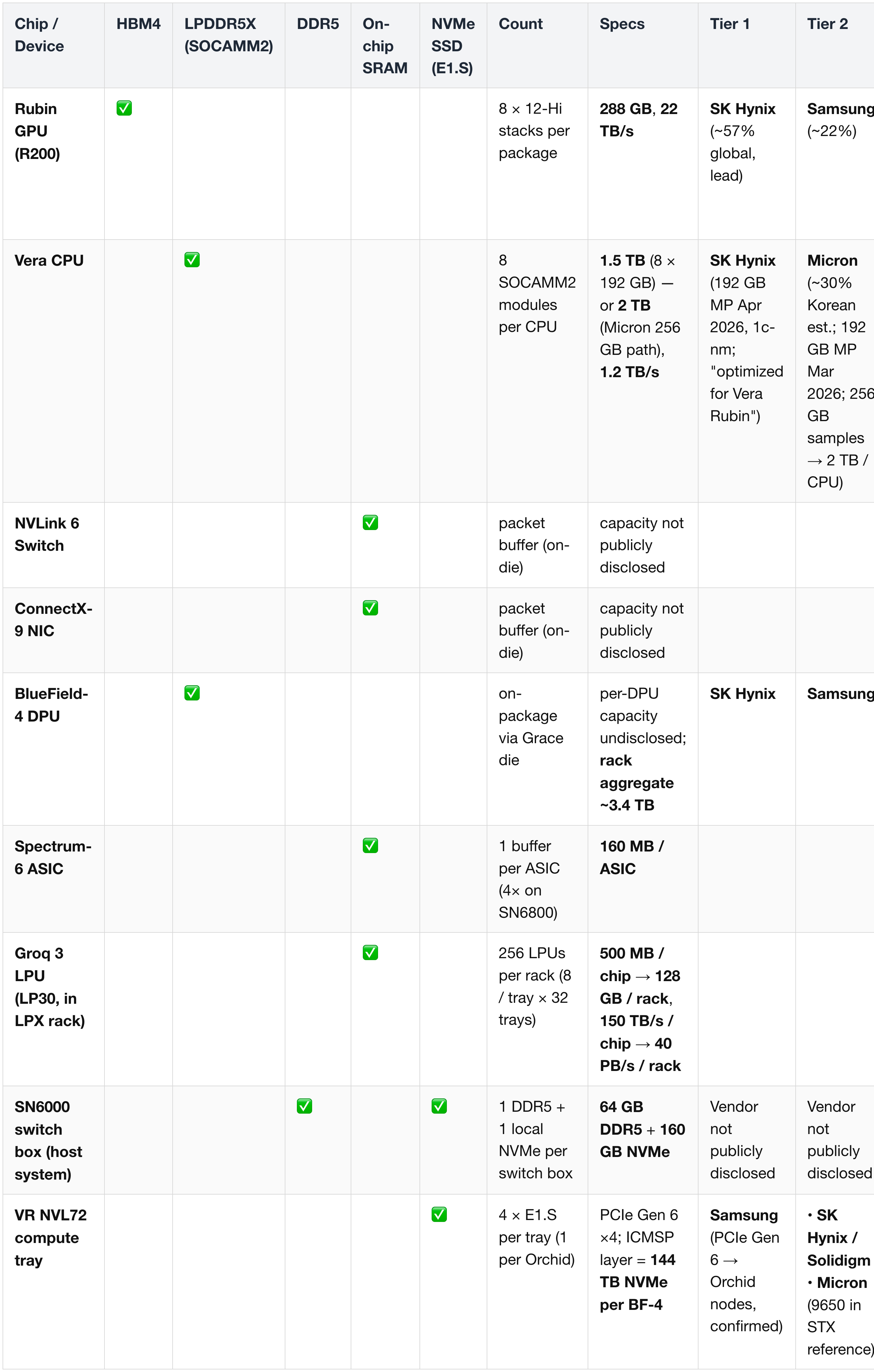
Key readouts:
- HBM4 is single-chip-concentrated — every gigabyte lands on a Rubin GPU package, making it the most concentrated memory bucket on the platform (and Hynix the highest-leverage memory supplier).
- LPDDR5X is two-chip-distributed — Vera CPU + BlueField-4 DPU split the rack-aggregate ~3.4 TB / rack; SOCAMM2 form factor only (no LPCAMM2 in Nvidia systems). All three Korean / US vendors qualified.
- Four chips ride SRAM-only — Groq LP30 (500 MB × 256 = 128 GB / rack), plus NVLink 6 Switch / CX-9 / Spectrum-6 packet buffers. The SRAM is foundry-embedded — no DRAM vendor exposure for these chips.
- NVMe is the most diversified bucket — five-vendor qualified pool (Samsung / Solidigm (subsidiary of SK Hynix) / Micron / Kioxia / SanDisk) for the E1.S layer on VR NVL72 compute trays, vs single-chip concentration on HBM. Operational risk is naturally spread.
(3) Cross-Subsystem Supplier Heatmap
Suppliers appearing across multiple subsystems (highest leverage to Vera Rubin). Memory vendors live in their own heatmap above (§ 10 (2)). ![[Pasted image 20260525144009.png]]
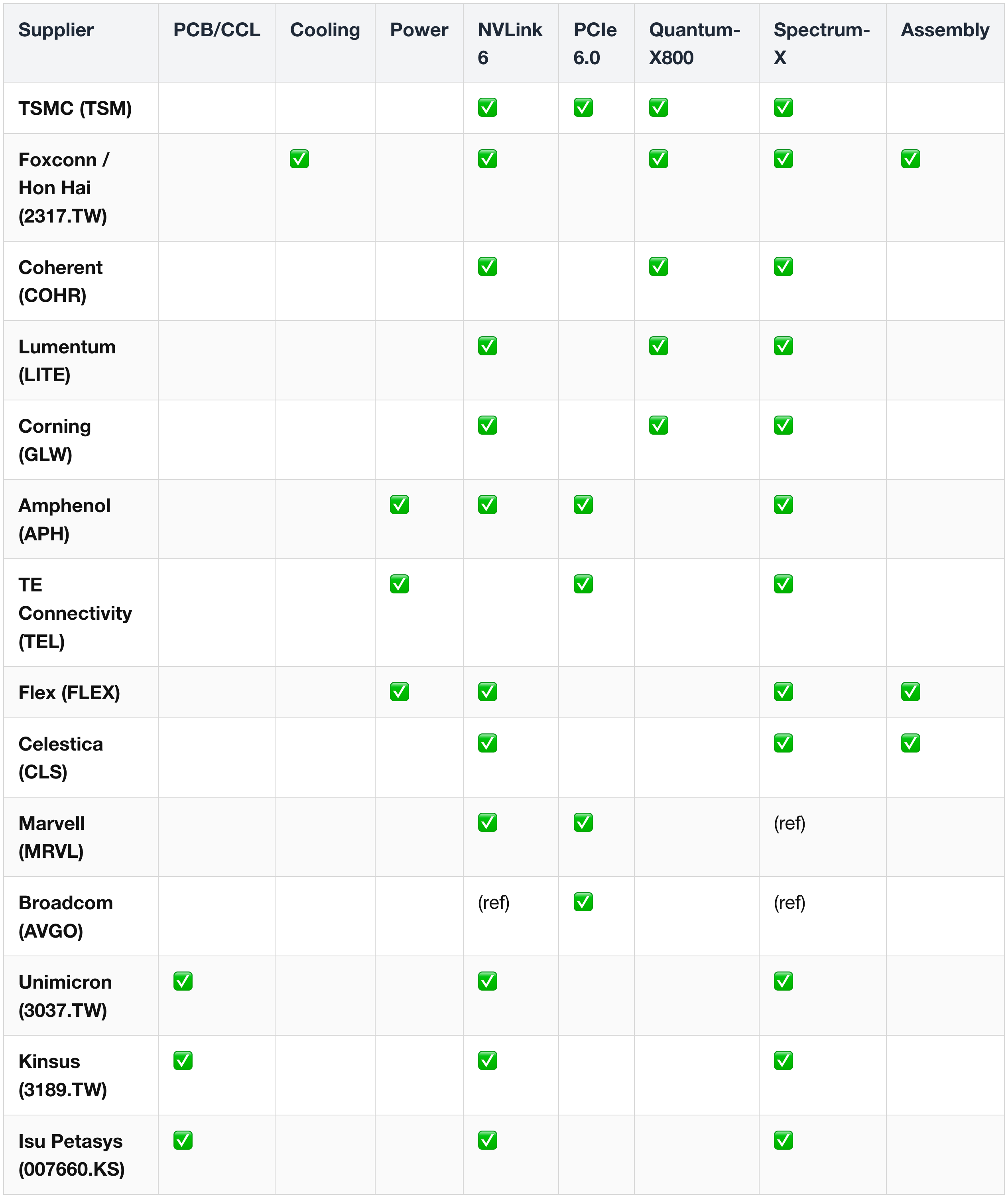
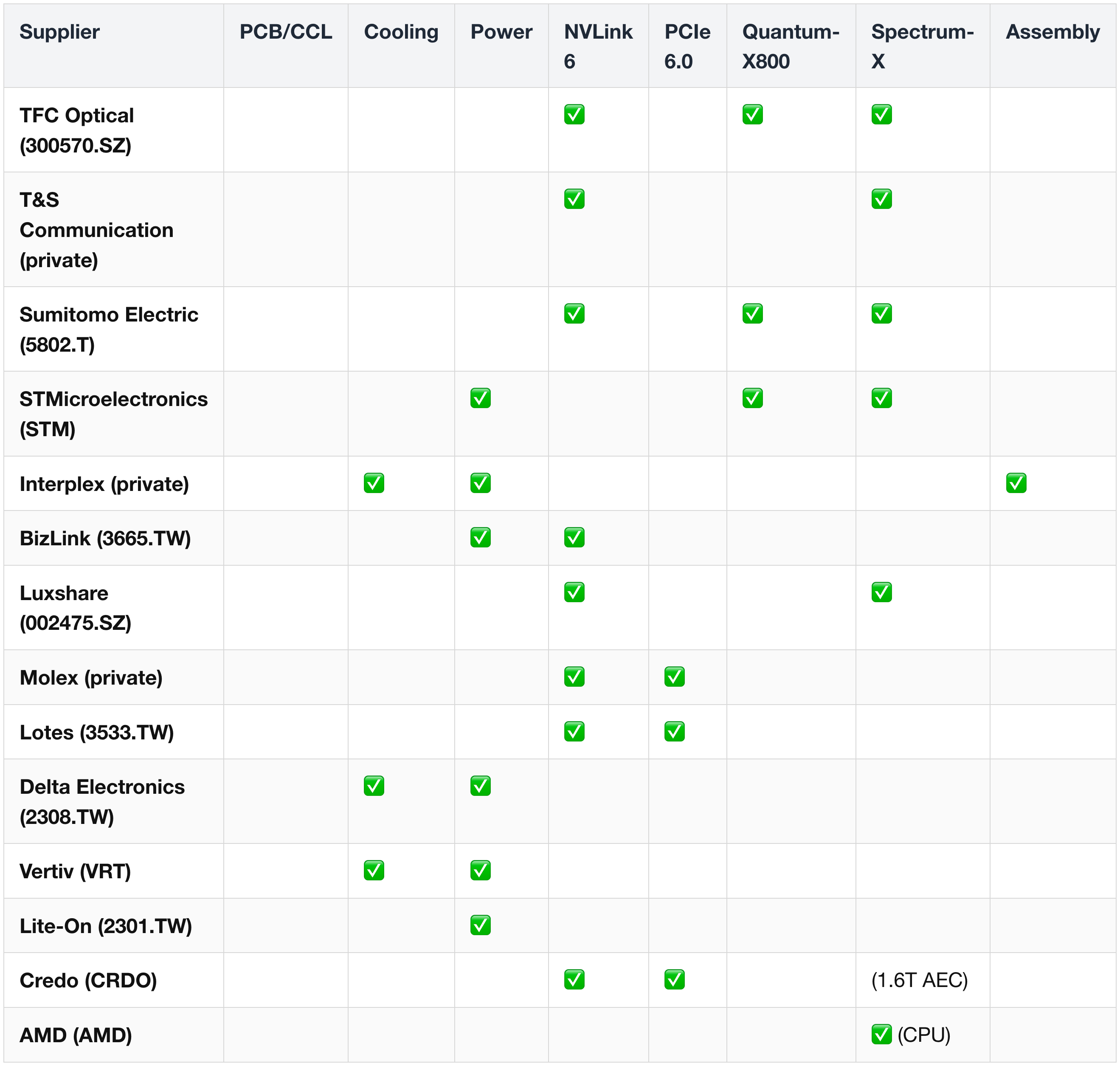
(ref) = referenced as competitive alternative, not a primary supplier.
Highest-leverage suppliers (appearing in 4+ subsystems):
- TSMC (TSM) — foundry leverage across silicon families.
- Foxconn / Hon Hai (2317.TW) — cooling, switch, assembly, networking.
- Coherent (COHR), Lumentum (LITE), Corning (GLW) — the optics trinity for both Quantum-X and Spectrum-X.
- Amphenol (APH), TE Connectivity (TEL) — interconnect across copper and optical.
Tier-2 leverage suppliers (appearing in 3 subsystems):
- STMicroelectronics (STM) — power semis + Quantum-X / Spectrum-X optical photonics (Starlight Consortium SiPho).
- Sumitomo Electric (5802.T) — fiber + MT ferrules across NVLink 6, Quantum-X, Spectrum-X CPO.
- Interplex (private) — cabinet + busbars + cold plates; one of three authorized Nvidia server-cabinet suppliers.
- Flex (FLEX) — 800 VDC power rack + NVLink 6 system integration + Spectrum-X + full-rack assembly.
- TFC Optical (300570.SZ) — FAU across NVLink 6, Quantum-X, Spectrum-X.
Where to Read What — Series Map
| Part | Title | Scope |
|---|---|---|
| 1 | Platform Framing & Architecture Map | Blackwell → Rubin platform thesis, headline specs |
| 2 | Rubin GPU — Engineering Deep Dive | Process node, SMs, HBM4, NVLink-C2C, package, CPX + Groq 3 LPX |
| 3 | Vera CPU & the Networking Silicon Family | Vera CPU, NVLink 6 Switch, ConnectX-9, BlueField-4, Spectrum-6 |
| 4 | Rack Assembly — Trays, PCB, and Cooling | HGX vs NVL72, compute tray modules, cableless midplane, PCB upgrade, liquid cooling |
| 5 | Rack Power and the Networking Fabric | Power delivery, HVDC, tray↔rack wiring, scale-up NVLink 6, scale-out InfiniBand + Ethernet |
| 6 | Supply Chain — Master Reference (this part) | Suppliers by subsystem across the entire stack |


